Os desafios modernos do reconhecimento de imagem e facial – e como a IA está facilitando soluções de ponta compactas e competitivas.
Embora o reconhecimento de imagem possa ser uma ferramenta poderosa para melhorar a segurança e a produtividade, os projetistas de sistemas enfrentam o desafio constante de fornecer classificações mais rápidas e precisas a partir de dispositivos menores e com menor consumo de energia. A tendência é responder a essa demanda com algoritmos de reconhecimento baseados em IA executados em microcontroladores minúsculos localizados na borda da IoT.
Este artigo analisa como o processamento de imagens está se tornando mais sofisticado, as tecnologias habilitadoras disponíveis e algumas possibilidades práticas de implementação com base no hardware e nos ecossistemas de vários fabricantes de semicondutores.
O reconhecimento de imagens, e seu principal subconjunto – o reconhecimento facial – tem sido amplamente utilizado em aplicações industriais e de segurança há muitos anos. No entanto, embora os usuários tenham começado a usar câmeras para reconhecimento de imagens porque a tecnologia permitia, os resultados eram frequentemente inadequados. As tentativas de classificar imagens podem ser prejudicadas por problemas como variação de escala ou perspectiva, elementos desordenados no fundo ou iluminação.
Portanto, existe sempre uma pressão para melhorar o desempenho desses sistemas, de modo que possam fornecer recursos de reconhecimento e classificação mais refinados, ao mesmo tempo que oferecem resultados mais robustos e precisos. E, à medida que tecnologias melhores se tornam disponíveis, surgem novas oportunidades para aumentar a produtividade ou a segurança.
Um excelente exemplo é o reconhecimento facial 3D. Os sistemas 2D já foram suficientes em aplicações como controle de acesso, até que as pessoas aprenderam a enganá-los usando técnicas de falsificação, como fotos de rostos. Assim, o reconhecimento 3D tornou-se necessário para superar essa limitação. Ele também resolve problemas como reconhecer pessoas que deixaram a barba crescer ou que estão usando óculos ou máscara de proteção contra a COVID-19.
A sofisticada tecnologia de reconhecimento de imagem está fazendo a diferença em áreas além da segurança. Na indústria, pode ser usada para melhorar a qualidade do produto em termos de forma, tamanho e cor, enquanto em aplicações automotivas, é aplicada na detecção de objetos na beira da estrada, na detecção de faixas, na detecção de animais, pessoas ou objetos em vias públicas. Também pode mapear a presença humana, por exemplo, em transportes públicos.
Hardware mais potente, aliado a softwares de IA cada vez mais sofisticados, também está possibilitando sistemas de reconhecimento de imagem com capacidade de detecção de humor. Por exemplo, fabricantes de automóveis podem usar a tecnologia de detecção de emoções faciais em carros inteligentes para alertar o motorista quando ele estiver com sonolência.
No entanto, os fabricantes de sistemas que buscam oferecer soluções mais poderosas e com baixa latência devem fazê-lo consumindo menos energia, espaço e custos. Devem manter-se tecnicamente competitivos e, ao mesmo tempo, adotar práticas sustentáveis.
Cada vez mais, a resposta tem sido migrar sistemas que antes rodavam em grandes servidores na nuvem para a borda da rede. Isso significa que algoritmos de IA agora são executados em minúsculos microcontroladores, que precisam mapear imagens recebidas com muita rapidez e precisão. Embora não seja tão importante na indústria, onde os robôs têm mais espaço e energia disponíveis, em outras aplicações essa tecnologia pode levar soluções poderosas de reconhecimento de imagem para os celulares e relógios de pulso dos usuários.
Executar sistemas de reconhecimento facial localmente na borda da rede, sem enviar dados para a nuvem, também resolve preocupações com a privacidade.

Conceitos tecnológicos e abordagens práticas para a construção de sistemas de reconhecimento de imagens na borda.
Do ponto de vista de um desenvolvedor de sistemas, um sistema de reconhecimento de imagem por IA, como qualquer outro produto eletrônico, é composto por diversos componentes de hardware e software que devem ser integrados em uma plataforma básica, a qual pode ser posteriormente desenvolvida em uma solução específica para a aplicação. Esses componentes incluem:
Câmera ou outro dispositivo de entrada: as câmeras utilizam diferentes tecnologias; a escolha da tecnologia da câmera afetará fundamentalmente todo o projeto do sistema.
Dispositivos de saída: Isso pode incluir um portão de segurança, que permite que um sistema de reconhecimento facial controle o acesso a uma área restrita; também pode haver um visor exibindo os resultados da análise de IA. Além disso, haverá uma conexão de rede se o sistema de reconhecimento de imagem fizer parte de uma infraestrutura maior.
Hardware de microcomputadores: Isso pode incluir apenas um processador principal, mas é mais provável que também tenha um acelerador de mecanismo de IA para melhorar o desempenho.
Algoritmo de IA: Muitas aplicações de reconhecimento de imagem podem usar o mesmo hardware, mas diferentes algoritmos de IA podem ser executados para atender a diferentes aplicações.
Para integrar esses componentes em um sistema de reconhecimento de imagem específico para uma aplicação, precisamos de
- Escolha uma tecnologia como reconhecimento facial 3D ou tempo de voo 3D para coletar dados de imagem de alta qualidade.
- Escolha um algoritmo de IA, como Redes Neurais Convolucionais (ConvNet/CNN), para extrair informações relevantes e acionáveis a partir dos dados brutos da imagem.
- Encontre um fabricante de semicondutores que ofereça o ambiente de hardware e desenvolvimento mais adequado à abordagem de coleta e processamento de imagens que você deseja adotar.
Coletando dados de imagem de alta qualidade
O reconhecimento facial 3D e o Time of Flight 3D são abordagens populares:
Reconhecimento facial 3D
O método de reconhecimento facial 3D utiliza sensores para capturar o formato do rosto com maior precisão. Ao contrário dos métodos tradicionais, a precisão do reconhecimento facial 3D não é afetada pela iluminação, e as varreduras podem ser feitas até mesmo no escuro. Outra vantagem do reconhecimento facial 3D é a capacidade de reconhecer um alvo a partir de múltiplos ângulos, e não apenas de um perfil frontal. Diferentemente do reconhecimento facial 2D, ele não pode ser enganado por fotografias utilizadas por pessoas que buscam acesso não autorizado a áreas restritas.
O iPhone X (e versões posteriores) vem com a tecnologia Face ID, que utiliza reconhecimento facial 3D para identificar o proprietário.
O processo de reconhecimento facial 3D possui seis etapas principais: Detecção, Alinhamento, Medição, Representação, Correspondência e Verificação ou Identificação.
Tempo de voo 3D
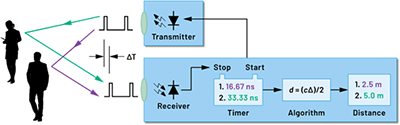
O tempo de voo 3D (ToF) é um tipo de LIDAR (detecção e alcance por luz) sem scanner que usa pulsos ópticos de alta potência com duração de nanossegundos para capturar informações de profundidade (normalmente em curtas distâncias) de uma cena de interesse.
Uma câmera ToF mede a distância iluminando ativamente um objeto com uma fonte de luz modulada, como um laser, e um sensor sensível ao comprimento de onda do laser para capturar a luz refletida. O sensor mede o atraso temporal Δ entre o momento em que a luz é emitida e o momento em que a luz refletida é recebida pela câmera. O atraso temporal é proporcional ao dobro da distância entre a câmera e o objeto (ida e volta), portanto, a distância pode ser estimada como profundidade = cΔ/2, onde c é a velocidade da luz.
Existem diferentes métodos para medir ∆T, dos quais dois se tornaram os mais prevalentes: o método de onda contínua (CW) e o método baseado em pulsos. Deve-se notar que a grande maioria dos sistemas ToF CW que foram implementados e estão atualmente no mercado utiliza sensores CMOS, enquanto os sistemas ToF pulsados utilizam sensores não-CMOS (notadamente CCDs).
Extraia informações relevantes e acionáveis dos dados brutos da imagem.
Após utilizar qualquer uma das tecnologias acima para capturar dados de imagem, precisamos de um algoritmo de IA para ser executado no hardware escolhido, a fim de analisar os dados e fornecer resultados significativos e acionáveis.
Uma abordagem é usar Redes Neurais Convolucionais (ConvNet/CNN): algoritmos de aprendizado profundo que podem receber uma imagem de entrada, atribuir importância (pesos e vieses treináveis) a vários aspectos/objetos na imagem e, em seguida, diferenciá-los uns dos outros.
O pré-processamento exigido em uma CNN é muito menor do que em outros algoritmos de classificação. Enquanto em métodos primitivos os filtros são projetados manualmente, com treinamento suficiente, as CNNs têm a capacidade de aprender esses filtros/características.
A arquitetura de uma CNN é análoga ao padrão de conectividade dos neurônios no cérebro humano e foi inspirada na organização do córtex visual.
Uma CNN (Rede Neural Convolucional) é capaz de capturar com sucesso as dependências espaciais e temporais em uma imagem através da aplicação de filtros relevantes. A arquitetura apresenta um melhor ajuste ao conjunto de dados de imagens devido à redução no número de parâmetros envolvidos e à reutilização de pesos. Em outras palavras, a rede pode ser treinada para compreender melhor a complexidade da imagem.
No entanto, outros algoritmos de aprendizado profundo também estão evoluindo rapidamente, com o uso de tipos de dados de menor precisão, como INT8, binário, ternário e dados personalizados.
Hardware e ecossistemas dos fabricantes de semicondutores
Independentemente do algoritmo de IA escolhido, para ser eficaz, ele deve ser executado em hardware adequado, capaz de fornecer a potência de processamento necessária sem exigir excessivamente energia elétrica, espaço, peso ou custo.
Em termos de implementações práticas de hardware, cada fabricante de semicondutores tende a oferecer seus próprios ecossistemas, baseados no hardware que desenvolveram, juntamente com softwares e ferramentas de desenvolvimento adequados. Ao decidir com qual fabricante de semicondutores trabalhar, os desenvolvedores devem estar cientes de que estão se comprometendo com o ecossistema de desenvolvimento do fabricante, bem como com seu hardware de processamento de imagem.
A seguir, analisamos soluções de reconhecimento de imagem de três líderes na área de hardware de IA – Analog Devices, Xilinx e NXP Semiconductors.
Dispositivos analógicos. A solução é baseada na família MAX78000, incluindo o MAX78002, um mecanismo de inferência de Rede Neural Convolucional (CNN) de ultrabaixo consumo de energia. A arquitetura avançada de sistema em chip do MAX78002 apresenta uma CPU Arm® Cortex®-M4 com FPU e um acelerador de rede neural profunda de ultrabaixo consumo de energia. (Veja o quadro: “O papel dos aceleradores de rede neural”.)
O núcleo RISC-V integrado pode executar códigos de aplicação e de controle, além de controlar o acelerador de CNN.
| O papel dos aceleradores de redes neurais. O aprendizado profundo é atualmente uma das abordagens de aprendizado de máquina mais proeminentes para resolver tarefas complexas que antes só podiam ser resolvidas por humanos. Em aplicações como visão computacional ou reconhecimento de fala, as redes neurais profundas (DNNs) alcançam alta precisão em comparação com algoritmos convencionais e, em alguns casos, até mesmo superior à de especialistas humanos. A maior precisão das DNNs em relação aos algoritmos convencionais decorre da capacidade de extrair características de alto nível dos dados de entrada após o uso de aprendizado estatístico em um grande número de dados de treinamento.A aprendizagem estatística leva a uma representação eficiente do espaço de entrada e a uma boa generalização. No entanto, essa capacidade exige um alto esforço computacional; contudo, ao aumentar o número de parâmetros, a precisão de uma rede pode ser aumentada. Consequentemente, a tendência em DNNs é claramente o crescimento exponencial do tamanho da rede. Isso leva a um aumento exponencial do esforço computacional e da quantidade de memória necessária.Portanto, as unidades centrais de processamento (CPUs) sozinhas são insuficientes para lidar com a carga computacional. Consequentemente, aceleradores de hardware com otimização estrutural são utilizados para aumentar o desempenho de inferência das redes neurais. Para a inferência de uma rede neural executada em dispositivos de borda, a eficiência energética é um fator importante que deve ser considerado, além da taxa de transferência. |
Como sucessor do MAX78000, o MAX78002 possui poder de computação e memória adicionais, e faz parte da nova geração de microcontroladores de inteligência artificial (IA) desenvolvidos para permitir a execução de redes neurais com consumo de energia ultrabaixo e na borda da internet das coisas (IoT).
Este produto combina o processamento de IA mais eficiente em termos de energia com os microcontroladores de ultrabaixo consumo de energia comprovados da Analog Devices. O acelerador de redes neurais convolucionais (CNN) baseado em hardware permite que aplicações alimentadas por bateria executem inferências de IA consumindo apenas microjoules de energia.

Você pode interagir com o microcontrolador usando o kit de avaliação MAX78002 (kit EV); este fornece uma plataforma para aproveitar os recursos do dispositivo e criar novas gerações de produtos de IA. O kit inclui hardware integrado, como um microfone digital, portas seriais, porta de vídeo digital (DVP) e suporte para módulo de câmera com interface serial (CSI), além de uma tela TFT colorida sensível ao toque de 3,5 polegadas.
O kit também inclui o circuito para monitorar e exibir o nível de energia no display TFT secundário. O MAX34417 monitora a tensão e a corrente do MAX78002 e reporta a energia acumulada para o MAX32625, usado como processador de dados de energia e também controla o display de energia.
Desenvolvimento de um modelo de identificação facial: Os projetistas podem criar modelos de identificação facial usando o fluxo de desenvolvimento da Analog Devices em PyTorch, treinados com diferentes conjuntos de dados abertos e implementados na placa de avaliação MAX78000. A Figura 4 mostra o fluxo de desenvolvimento.
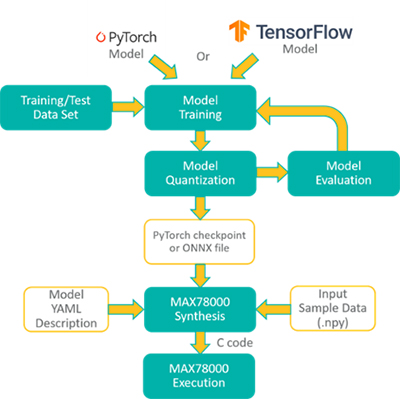
O processo de desenvolvimento resolve o problema de identificação facial em três etapas principais:
- Extração de faces: Detecção de rostos na imagem para extrair uma subimagem retangular que contenha apenas um rosto.
- Alinhamento facial: Determinação dos ângulos de rotação (em 3D) do rosto na subimagem para compensar seu efeito por meio de transformação afim.
- Identificação facial: Identificação da pessoa utilizando a subimagem extraída e alinhada.
Xilinx utiliza uma abordagem de hardware diferente, baseada no seu SOM (System on Module) Kria K26. O SOM foi projetado para permitir que os desenvolvedores, em seu ambiente de design preferido, implementem seus aplicativos de visão inteligente mais rapidamente, com um kit de desenvolvimento pronto para uso e de baixo custo.
O módulo K26 SOM é ideal para aplicações Edge, pois sua arquitetura Zynq MPSoC subjacente oferece alto desempenho por watt e baixo custo de propriedade. Os módulos Kria SOM são configuráveis por hardware, o que os torna escaláveis e preparados para o futuro.
O design do dispositivo oferece ainda mais vantagens de desempenho:
Poder computacional bruto: O K26 pode ser configurado com diversas unidades de processamento de aprendizado profundo (DPUs), e, com base nos requisitos de desempenho, a configuração mais adequada pode ser integrada ao projeto. Como exemplo, a DPU B3136 a 300 MHz tem um desempenho máximo de 0,94 TOPS.
Suporte a tipos de dados de menor precisão: Com a rápida evolução dos algoritmos de aprendizado profundo, tipos de dados de menor precisão, como INT8, binário, ternário e dados personalizados, estão sendo cada vez mais utilizados. Para os fabricantes de GPUs, atender às necessidades atuais do mercado é um desafio, pois precisam modificar/ajustar suas arquiteturas para acomodar o suporte a tipos de dados personalizados ou de menor precisão. O módulo Kria K26 SOM suporta uma gama completa de precisões de dados, como FP32, INT8, binário e outros tipos de dados personalizados – e operações com tipos de dados de menor precisão demonstraram consumir muito menos energia.
Baixa latência e baixo consumo de energia: A arquitetura Zynq MPSoC, com sua capacidade de reconfiguração, permite que os desenvolvedores projetem seus aplicativos com acesso reduzido ou nulo à memória externa. Isso não só ajuda a reduzir o consumo geral de energia do aplicativo, como também aumenta a capacidade de resposta com latências de ponta a ponta mais baixas.
Flexibilidade: ao contrário das GPUs, onde o fluxo de dados é fixo, o hardware da Xilinx oferece flexibilidade para reconfigurar o caminho de dados de forma exclusiva, alcançando o máximo desempenho e menores latências. Além disso, o caminho de dados programável reduz a necessidade de processamento em lote, que é uma grande desvantagem das GPUs e se torna um dilema entre menores latências e maior desempenho.
Para avaliação e desenvolvimento, a Xilinx oferece o kit inicial KV260, que inclui um módulo Kria K26 acoplado a uma placa de expansão focada em visão computacional. A combinação dessa plataforma de hardware de visão pré-definida com um conjunto de software robusto e abrangente, baseado em Yocto ou Ubuntu, e com aplicativos acelerados com suporte a visão computacional, proporciona aos desenvolvedores um caminho sem precedentes para aproveitar as tecnologias da Xilinx na construção de sistemas.
Após a conclusão do desenvolvimento, a personalização para implantações de produção é simples. O Kria SOM é acoplado a uma placa de expansão simples, projetada pelo usuário final, que incorpora a conectividade e os componentes adicionais específicos para o seu sistema de destino.

Exemplo de aplicação: A Xilinx firmou uma parceria com a Uncanny Vision, líder do setor em soluções de análise de vídeo para cidades inteligentes, com o objetivo de fornecer ao mercado uma solução de reconhecimento automático de placas de veículos (ANPR) de classe mundial. A aplicação está sendo amplamente adotada em diversas cidades ao redor do mundo como parte da implementação de cidades inteligentes.
O aplicativo ANPR é um pipeline baseado em IA que inclui decodificação de vídeo, pré-processamento de imagem, aprendizado de máquina (detecção) e reconhecimento de caracteres OCR. A Figura 6 mostra os componentes básicos do aplicativo.

Semicondutores NXP: A NXP expandiu seu portfólio EdgeReady, adicionando uma solução para reconhecimento facial seguro que utiliza uma câmera 3D de módulo de luz estruturada (SLM) de alto desempenho combinada com o microcontrolador crossover i.MX RT117F. Esta é a primeira solução a combinar uma câmera 3D SLM com um microcontrolador para oferecer o desempenho e a segurança do reconhecimento facial 3D na borda, eliminando assim a necessidade de usar uma implementação Linux cara e com alto consumo de energia em uma unidade de processamento (MPU), como é tradicionalmente exigido com câmeras 3D de alto desempenho.
A mais recente solução EdgeReady permite que desenvolvedores de fechaduras inteligentes e outros sistemas de controle de acesso adicionem reconhecimento facial seguro baseado em aprendizado de máquina de forma rápida e fácil a produtos para casas e edifícios inteligentes. A solução oferece reconhecimento facial 3D confiável em aplicações internas e externas, em diversas condições de iluminação, incluindo luz solar intensa, luz noturna fraca ou outras condições de iluminação difíceis que representam um desafio para os sistemas tradicionais de reconhecimento facial.
O uso de uma câmera 3D SLM permite a detecção avançada de vivacidade, ajudando a distinguir uma pessoa real de técnicas de falsificação, como uma fotografia, máscara imitadora ou modelo 3D, para evitar acesso não autorizado.
O i.MX RT117F utiliza um modelo avançado de aprendizado de máquina como parte do software de aprendizado de máquina eIQ da NXP, executado em seu núcleo de CPU de alto desempenho, o que permite um reconhecimento facial mais rápido e preciso para melhorar tanto a experiência do usuário quanto a eficiência energética.
Semelhante à solução NXP EdgeReady baseada no microcontrolador i.MX RT106F para reconhecimento facial seguro, a detecção avançada de vivacidade e o reconhecimento facial são realizados localmente na borda da rede, permitindo que os dados biométricos pessoais permaneçam no dispositivo. Isso ajuda a atender às preocupações do consumidor com a privacidade, além de eliminar a latência associada às soluções baseadas em nuvem.
Conclusão
O artigo acima discutiu as tecnologias disponíveis para o desenvolvimento de sistemas aprimorados de reconhecimento de imagem e apresentou exemplos de diferentes plataformas de hardware de fabricantes de semicondutores e ecossistemas de desenvolvimento disponíveis para a implementação dessas tecnologias.
Com isso, fica evidente que a abordagem de cada fabricante é muito diferente, em termos de implementações de hardware e componentes já disponíveis. Outros fabricantes, que não são abordados neste artigo, também oferecem suas próprias soluções.
Portanto, faz sentido consultar um fornecedor como a Farnell, que tem acesso a uma ampla gama de fabricantes e soluções. Temos especialistas que podem discutir os fatores a serem considerados na escolha da arquitetura de hardware e do ambiente de desenvolvimento adequados, e também na transição para a produção.
Contato da Newark no Brasil
Para mais informações e adquirir componentes, contate a LATeRe, representante da Newark, pelo telefone (11) 4066-9400 ou e-mail: [email protected]
* Texto originalmente publicado em: link