Introdução
Com os avanços em modelos de linguagem para dispositivos embarcados, torna-se possível integrar Small Language Models (SLMs) a sistemas IoT para criar aplicações inteligentes capazes de interpretar comandos de linguagem natural, executar ações e responder com naturalidade.
Neste artigo, vamos demonstrar como integrar um SLM rodando em um servidor Python com a Franzininho WiFi Lab01, permitindo o controle IoT via API externa.
O exemplo utilizado baseia-se nos exemplos do livro Edge AI Engineering Hands-on with the Raspberry Pi do professor Marcelo Rovai.
Para conhecer mais sobre a Franzininho consulte sua documentação em Franzininho WiFi LAB01 | Franzininho
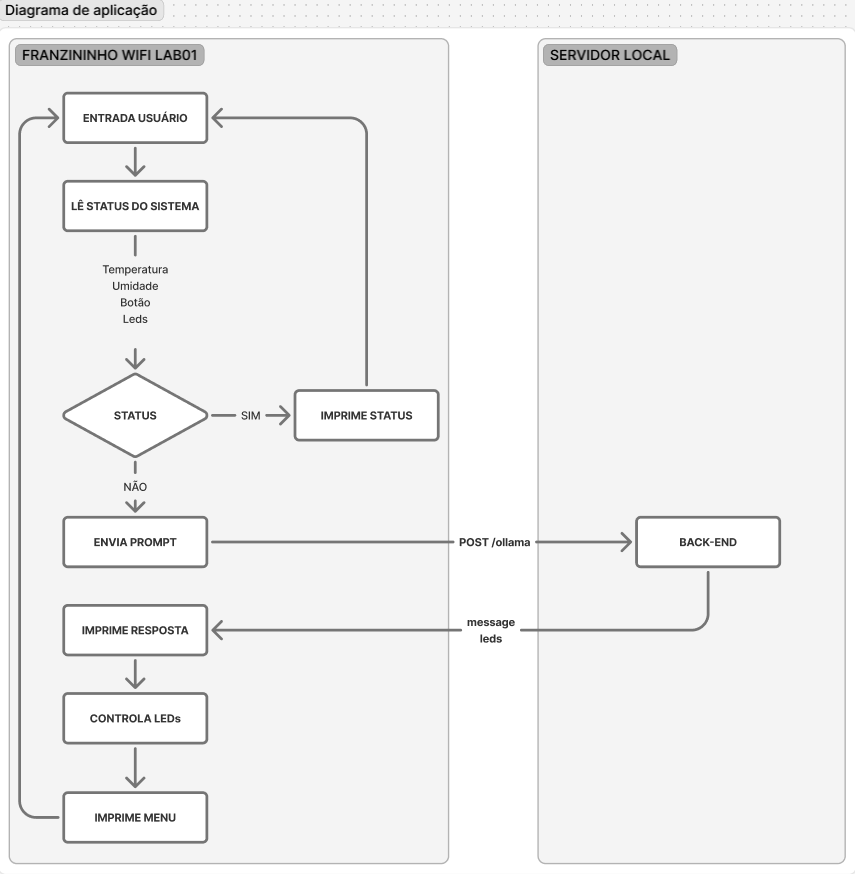
Diagrama de aplicação
Materiais Necessários
Para desenvolver nossa aplicação os materiais utilizados foram:
- Placa Franzininho WiFi Lab01
- Cabo USB-C
- Arduino IDE
- Python
- API Ollama
Gerar API Key no Ollama
- Vá em Ollama keys · Settings
- Clique em Add API Key (Adicionar chave API).
- Copie a chave gerada e utilize no seu projeto.
Circuito

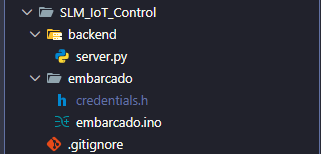
Estrutura do Projeto
O projeto foi organizado em pastas independentes, de acordo com a função de cada parte do sistema.
Backend
Contém a API responsável por receber os dados da Franzininho WiFi LAB01, chamar a API do Ollama e retornar nossa resposta.
Abaixo temos o trecho principal, responsável por definir a rota POST e executar nosso fluxo.
@app.route("/ollama", methods=["POST"])
def ollama():
body = rq.get_json()
# Create prompt with user input
system_prompt = create_interactive_prompt(
body["temperature"],
body["humidity"],
body["btn_pressed"],
body["led_red"],
body["led_blue"],
body["led_green"],
body["user_input"]
)
# Get SLM response
response = slm_inference(system_prompt, model)
#Parse response
message,(red, blue, green) = parse_interactive_response(response)
return jsonify({
"message": message,
"red_led": red,
"blue_led": blue,
"green_led": green
})
A ideia é criar um prompt contendo os dados atuais, instruções, regras, exemplos e modelo de resposta da IA.
Em seguida, fazemos a requisição conforme a documentação da API Ollama nos sugere.
def slm_inference(PROMPT, MODEL):
payload = {
"model": MODEL,
"messages": [{"role": "user", "content": PROMPT}],
"stream": False
}
# Make the API request to Ollama Cloud
response = requests.post(
url="https://ollama.com/api/chat",
headers={
"Authorization": f"Bearer {SECRET_KEY}",
"Content-Type": "application/json",
},
data=json.dumps(payload)
)
return response.json().get("message", {}).get("content", "No response provided.")Por fim, é extraído somente as informações pertinentes para a aplicação, como a resposta da IA e os estados dos Leds definidos.
Embarcado
Inclui o código que roda na Franzininho WiFi LAB01.
Abaixo temos a função que recebe os dados de temperatura, umidade, estado do botão, estado dos leds e o texto do usuário. Em seguida, monta uma requisição HTTP do tipo POST e envia para o nosso servidor backend na rota /ollama. A seguinte rota irá nos retornar um JSON com os campos, message, red_led, blue_led, e green_led. Isso, será passado para a função de atuação.
struct responseLLM sendToLlm(float temp, float hum, bool button_state, bool ledRed, bool ledBlue, bool ledGreen, String input)
{
struct responseLLM response;
HTTPClient http; // Create an HTTP client instance
http.begin((serverPath + "/ollama").c_str()); // Start the connection to the server on the route
http.addHeader("Content-Type", "application/json"); // Add the Content-Type header
// Create request JSON
DynamicJsonDocument doc(1024);
doc["temperature"] = temp;
doc["humidity"] = hum;
doc["btn_pressed"] = button_state;
doc["led_red"] = ledRed;
doc["led_blue"] = ledBlue;
doc["led_green"] = ledGreen;
doc["user_input"] = input;
String jsonRequest;
serializeJson(doc, jsonRequest);
// Send request
int httpCode = http.POST(jsonRequest);
if (httpCode != HTTP_CODE_OK)
{
Serial.printf("[HTTP] ERROR: Code %d - %s\n",
httpCode, http.errorToString(httpCode).c_str());
http.end();
response.message = "Error: Invalid server response";
return response;
}
// Process response
String jsonResponse = http.getString();
http.end();
DynamicJsonDocument responseDoc(1024);
DeserializationError error = deserializeJson(responseDoc, jsonResponse);
if (error)
{
Serial.print(F("[HTTP] ERROR: Failed to parse JSON: "));
Serial.println(error.c_str());
response.message = "Error: Invalid server response";
return response;
}
// Extrair dados da resposta
response.message = responseDoc["message"] | "Sem resposta";
response.leds.red = responseDoc["red_led"] | false;
response.leds.blue = responseDoc["blue_led"] | false;
response.leds.green = responseDoc["green_led"] | false;
return response;
}
// Send data to the LLM and get the response
struct responseLLM response = sendToLlm(data.temperature, data.humidity, data.buttonPressed, ledSts.red, ledSts.blue, ledSts.green, input);
// Get SLM response
Serial.println("\nAssistant: [Thinking...]");
// Display assistant's message
Serial.println("Assistant: " + response.message);
// Control LEDs based on response
setLeds(response.leds.red, response.leds.blue, response.leds.green);
O código completo pode ser consultado em: Edge_AI/SLM_IoT_Control at main · guilhermefernandesk/Edge_AI
Resultados

Conclusão
Neste artigo, demonstramos como integrar um SLM rodando em um servidor Python com a Franzininho WiFi Lab01, criando um sistema IoT inteligente capaz de executar comandos de linguagem natural.
Essa arquitetura pode ser expandida para:
- Controle de automação residencial
- Chatbots físicos com hardware embarcado
- Assistentes embarcados integrados a sensores
- Processamento local sem depender da nuvem
- Dispositivos IoT inteligentes capazes de interpretar texto
Sinta-se à vontade para compartilhar seus resultados com a comunidade, seja por artigos, vídeos ou repositórios abertos. Sua experiência pode inspirar e auxiliar muitos outros desenvolvedores.