Introdução
Engenheiros e estudantes passam horas na bancada, realizando cálculos, projetos, soldagens, simulações e estudos intensivos. No meio dessa rotina, é comum se cansarem, consultarem documentações e ignorarem condições do ambiente.
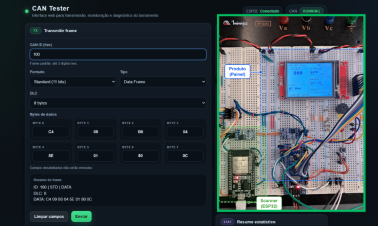
Neste artigo, vamos demonstrar como criar um ambiente de estudo mais produtivo, utilizando a Franzininho WiFi Lab01 com servidor Python para comandos como: “Inicie um pomodoro de 10 minutos”, “O ambiente está bom para estudar?”, “Coloque o servo em 45º, “Ligue o Led Azul”, “Qual pino está o DHT11 na Franzininho?” e entre outras opções.
O projeto apresenta uma aplicação para produtividade utilizando um SLM (Small Language Model), combinado com RAG (Retrieval-Augmented Generation) para consulta de documentação técnica da Franzininho WiFi Lab01. A solução responde comandos em linguagem natural e executa as ações solicitadas para controlar os periféricos da placa.
O exemplo utilizado baseia-se nos exemplos do livro Edge AI Engineering Hands-on with the Raspberry Pi do professor Marcelo Rovai.
Para conhecer mais sobre a Franzininho consulte sua documentação em Franzininho WiFi LAB01 | Franzininho
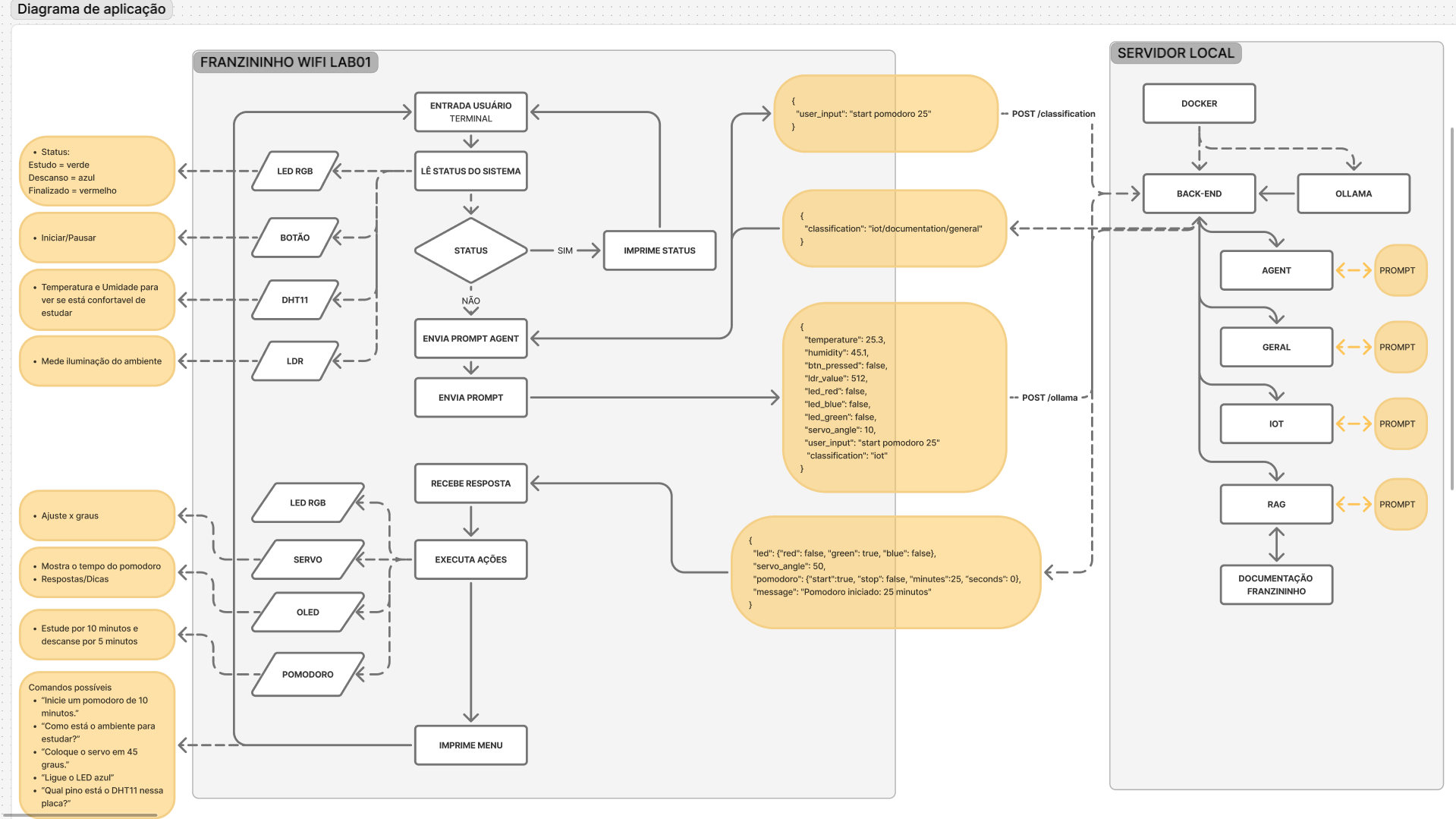
Diagrama de aplicação
Tecnologias utilizadas
- Python
- Ollama
- Flask
- Docker
- Gemma3
Materiais Necessários
Para desenvolver nossa aplicação os materiais utilizados foram:
- Placa Franzininho WiFi Lab01
- Cabo USB
- Arduino IDE
Circuito

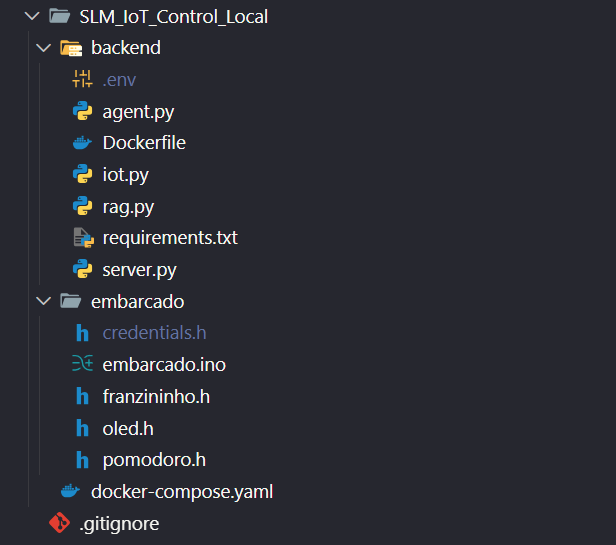
Estrutura do Projeto
O projeto foi organizado em pastas independentes, de acordo com a função de cada parte do sistema.
Backend
Contém a API responsável por receber os dados da Franzininho WiFi Lab01, chamar a API, Ollama e retornar nossa resposta.
Para lidarmos com tempo de timeout entre requisições HTTP, foi criado um rota de classificação entre as classes: iot, documentação e geral. A ideia é criar um prompt para cada, contendo os dados atuais, instruções, regras, exemplos e modelo de resposta da IA.
@app.route("/ollama", methods=["POST"])
def ollama():
body = rq.get_json()
classification = body["classification"]
if classification == "iot":
message,(red, blue, green), servo_angle, (pomodoro_start, pomodoro_stop, pomodoro_minutes), response = useIOT.query(body)
return jsonify({
"message": message,
"red_led": red,
"blue_led": blue,
"green_led": green,
"servo_angle": servo_angle,
"pomodoro": {
"start": pomodoro_start,
"stop": pomodoro_stop,
"minutes": pomodoro_minutes,
},
"response": response
})
elif classification == "documentation":
message = useRAG.query(body["user_input"])
return jsonify({
"message": message
})
else:
message = useAGENT.ask_ollama(body["user_input"])
return jsonify({
"message": message
})
Na classe de RAG, passamos a url da documentação que será armazenada em pedaços para consulta da IA posteriormente.
Em seguida, fazemos a requisição conforme a documentação da API Ollama nos sugere. Abaixo temos o exemplo de prompt e inferência para a classe IOT.
You are an IoT SLM controller. Always respond ONLY with valid JSON.
SYSTEM STATUS:
- temperature: {temp:.1f}
- humidity: {hum:.1f}
- button_pressed: {str(button_state).lower()}
- leds: red={str(ledRed).lower()}, blue={str(ledBlue).lower()}, green={str(ledGreen).lower()}
- ldr_value: {ldrValue}
- servo_angle: {servoAngle}
RULES:
1. Output ONLY this JSON structure:
{{
"message": "",
"leds": {{
"red_led": bool,
"green_led": bool,
"blue_led": bool
}},
"servo_angle": int,
"pomodoro": {{
"start": bool,
"stop": bool,
"minutes": int
}}
}}
2. Do NOT add any text outside the JSON.
3. If the user asks for information, keep all hardware states unchanged.
4. If the user requests an action, update the states.
5. Only ONE LED may be ON unless the user explicitly requests multiple.
6. If the user asks about the environment, evaluate study productivity based on SYSTEM STATUS.
7. Keep "message" short and clear.
USER INPUT: "{user_input}"
"""
def slm_inference(self, PROMPT):
response = self.session.post(
url=f"{self.ollama_host}/api/generate",
json={
"model": "gemma3",
"prompt": PROMPT,
"stream": False,
"format":"json",
}
)
return response.json().get("response", {})Por fim, temos o arquivo Dockerfile responsável por definir como será construído o container. No caso do backend, utilizamos o python para servir o servidor na porta 5000
FROM python:3.11-slim
# define diretório de trabalho
WORKDIR /usr/src/app
# copia dependências
COPY requirements.txt .
# instala dependências
RUN pip install --no-cache-dir -r requirements.txt
# permite prints no container
ENV PYTHONUNBUFFERED=1
# copia o projeto
COPY . .
# expõe a porta do flask
EXPOSE 5000
# comando para executar
CMD ["python", "server.py"]Embarcado
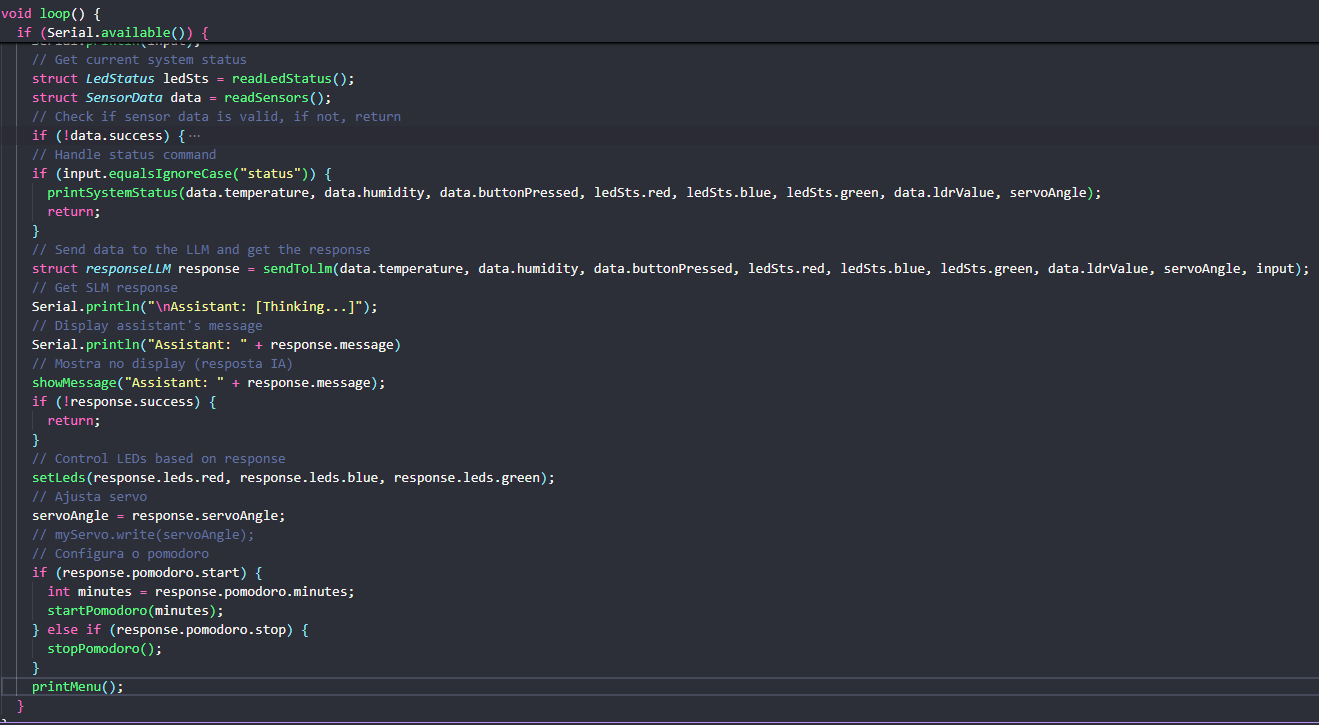
Inclui o código que roda na Franzininho WiFi Lab01.
Abaixo temos a função que recebe os dados de temperatura, umidade, estado do botão, estado dos leds e o texto do usuário. Em seguida, monta uma requisição HTTP do tipo POST e envia para o nosso servidor backend na rota /classification e depois /ollama. A seguinte rota irá nos retornar um JSON que será passado para a função de atuação.
Docker compose
Aqui ficam os arquivos de configuração do Docker Compose, que permitem subir rapidamente todo o sistema (backend e ollama) em containers.
- Com um único comando (docker-compose up), todo o ambiente é inicializado.
- Isso garante reprodutibilidade e facilita a implantação em servidores locais ou na nuvem.
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
ports:
- "11434:11434"
volumes:
- ollama_data:/root/.ollama
entrypoint: >
bash -c "
ollama serve &
sleep 3 &&
if ! ollama list | grep -q 'gemma3'; then
echo 'Baixando modelo gemma3...';
ollama pull gemma3;
ollama pull nomic-embed-text;
else
echo 'Modelo gemma3 já está instalado.';
fi &&
wait
"
backend:
build:
context: ./backend
dockerfile: Dockerfile
container_name: backend_python
ports:
- "5000:5000"
env_file:
- ./backend/.env
depends_on:
- ollama
volumes:
ollama_data:O código completo pode ser acessado em: Edge_AI/SLM_IoT_Control_Local at main · guilhermefernandesk/Edge_AI
Resultados
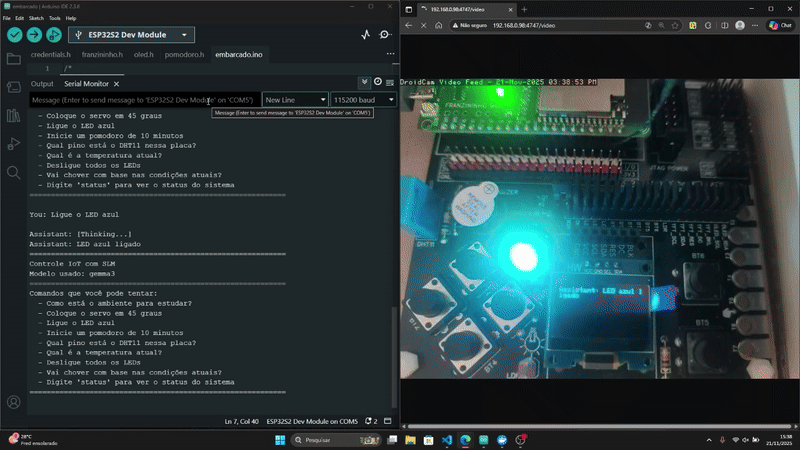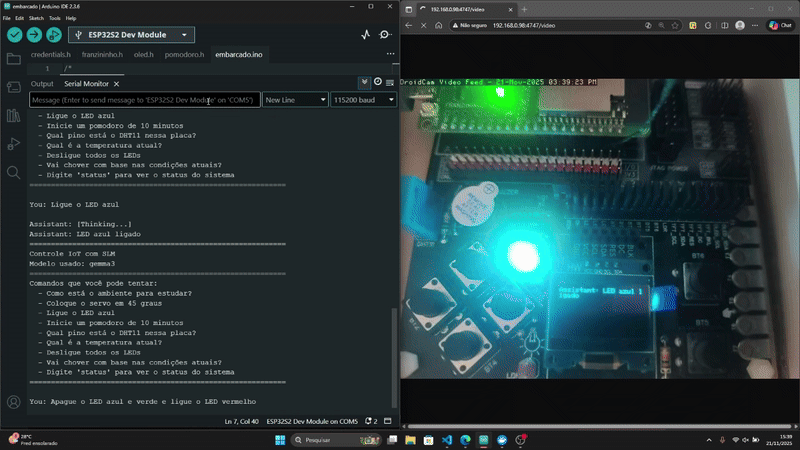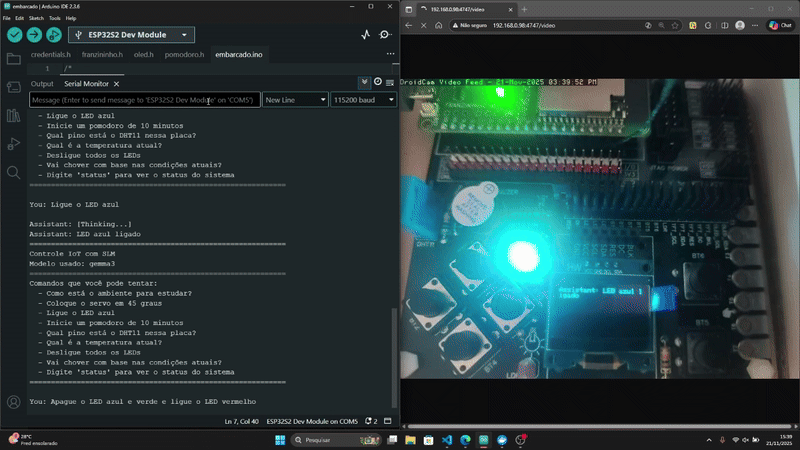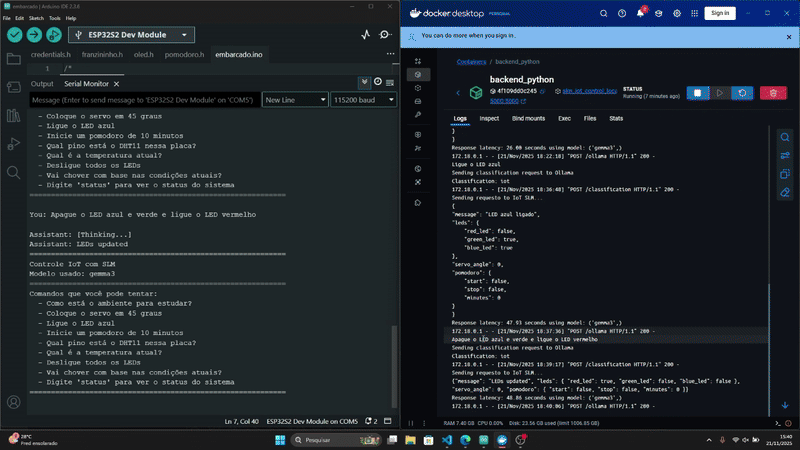
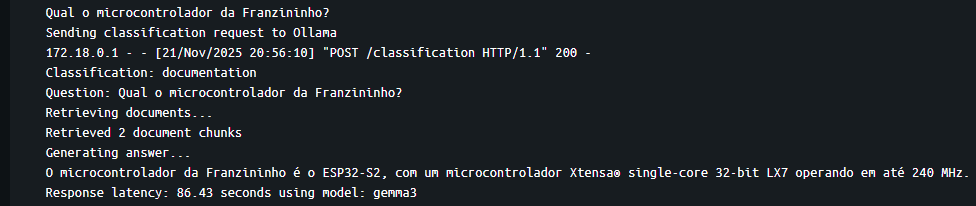
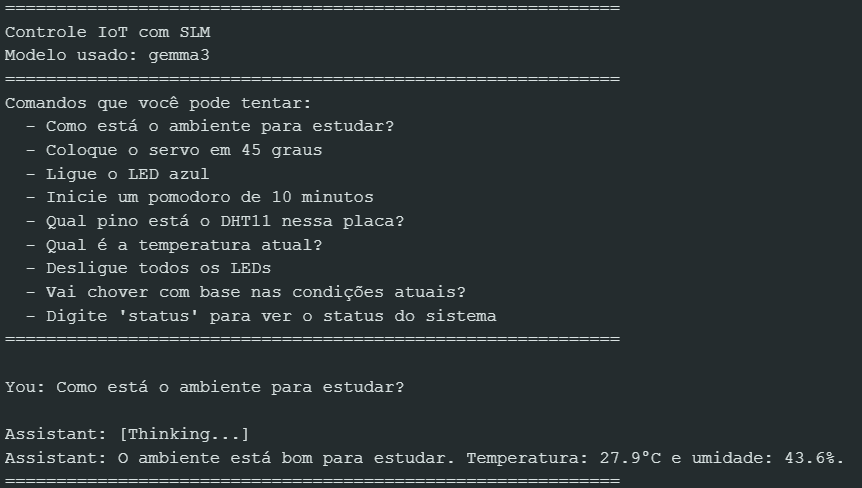
Conclusão
Neste artigo, demonstramos como integrar um SLM rodando em um servidor Python com a Franzininho WiFi Lab01, criando um sistema IoT inteligente capaz de executar comandos de linguagem natural.
Essa arquitetura pode ser expandida para:
- Controle de automação residencial
- Chatbots físicos com hardware embarcado
- Assistentes embarcados integrados a sensores
- Processamento local sem depender da nuvem
- Dispositivos IoT inteligentes capazes de interpretar texto
Sinta-se à vontade para compartilhar seus resultados com a comunidade, seja por artigos, vídeos ou repositórios abertos. Sua experiência pode inspirar e auxiliar muitos outros desenvolvedores.