
Olá caro leitor, não, eu sei, este não é mais um post sobre controle digital ou processamento de sinais, fato é que além desses dois ramos super legais relacionadas a engenharia embarcada, estou também a compartilhar técnicas e soluções de firmware do meu dia-a-dia. No assunto de hoje falaremos sobre um tópico polêmico no ponto de vista de software para máquinas de poucos recursos, memória dinâmica! Sim, você não entendeu errado, aquele malloc() e free() que professores e colegas de profissão nos dizem pra nunca usar pelos mais variados motivos. Apresentaremos aqui um pequeno gerenciador de memória capaz de operar em tempo real (ou seja, ele garante o tempo de execução constante para qualquer que seja o tamanho do bloco desejado) e com bons resultados em termos de desperdício de memória, a fragmentação. Eis que o gerenciador é chamado TLSF – “Two Level Segregate Fit“.
Mas vale a pena usar alocação dinâmica em um sistema embarcado?
Provavelmente essa deve ser a primeira pergunta que o leitor deve fazer. Como já disse antes esse é um assunto cujas opiniões divergem bastante entre profissionais, entusiastas e professores. Muitos dizem que é legal possuir uma forma de reservar memória e liberar depois para uso futuro, outros postulam em jamais usar tal técnica por causa dos overheads envolvidos, e pelo perigo de alocar memória sem liberar depois e bagunçar todo o Heap (região comumente reservada no linker para ser usada para alocação e liberação dinâmica). O objetivo deste artigo não é discutir quem está certo mas sim assumir que usar alocação dinâmica em sistemas embarcados de tempo real pode ser interessante e apresentar uma alternativa a alguns dos desafios que esse tipo de módulo costuma oferecer na sua implementação. Para estimular o leitor, a alocação dinâmica de memória tem basicamente alguns benefícios a seguir:
- Reutilização de memória em caso de variáveis temporárias (exemplo, structs criadas somente dentro de uma função);
- Facilidade para implementação de estrutura de dados de tamanhos variáveis (Queues ou Stacks baseados em listas ligadas);
- Ajuda demais a implementar tópicos de orientação a objeto;
- Especificamente o TLSF pode susbtituir o operador new em C++ (ou outra linguagem), tornando a criação de objetos computacionalmente mais leve.
Ok, de posse dessa visão a respeito de gerenciar memória em vez de alocar todas as nossas variáveis em tempo de compilação, vamos dar uma olhada no que o TLSF tem para nos oferecer em termos de diferencial.
O gerenciador de memória com complexidade O(1)
Quem já utilizou gerenciamento de memória em algum projeto de firmware, sabe que esse tipo de módulo possui alguns desafios de implementação. O primeiro que vem à cabeça é justamente a incerteza do tempo de execução, ou seja, ao efetuar um malloc() o tempo que essa função irá levar para executar vai variar demais em função do tamanho do bloco solicitado e do estado da região usada como heap, podendo levar ora 10 ciclos, ora 100. Esse tipo de comportamento é inadmissível para um sistema de tempo real, ah e detalhe, pode variar sua execução e ainda pode retornar uma belo ponteiro nulo representando que está sem memória, frustrante não?
O segundo ponto que envolve constantemente o uso do gerenciador de memória, é o quão bem ele a gerencia. Após uma bateria de execução de malloc() e free() qual a porcentagem da região do heap continua reutilizável, ou seja, quanto dessa região foi fragmentada. O terceiro ponto trata do overhead necessário para gerenciar um bloco de B bytes, ou seja, além da região de memória de tamanho B bytes que queremos gerenciar, quantos bytes extras devo adicionar a essa região para armazenar as estruturas de controle da memória a ser gerenciada. O quarto e último ponto trata da política da adequação do tamanho de bloco obtido ao tamanho requisitado, podendo ser:
- Best Fit: O bloco possui exatamente o mesmo tamanho do que foi requisitado, ignorando qualquer problema de desalinhamento de memória, permitindo assim zero de desperdício de heap;
- Good Fit: O bloco possui o tamanho pelo menos igual, ou maior ao requisitado, sendo adequando mas tolerando algum desperdício para lidar com problemas como desalinhamento de memória;
- First Fit: O bloco requisitado possui tamanho pelo menos igual ou maior à necessidade, sendo o primeiro bloco a satisfazer essa condição, ignorando qualquer possível problema com desperdício de memória.
Agora que conhecemos um pouco os desafios de se implementar um gerenciador de memória (em especial em sistemas embarcados), apresentamos o gerenciador TLSF, escrito originalmente por Miguel Masmano. Como sua tese de doutorado, ele implementou um gerenciador de memória que contorna muito bem todos os desafios apresentados, sendo suas principais características:
- Tempo real: O tempo de execução para alocar e desalocar memória é sempre constante, independente do tamanho do bloco requisitado;
- Razoável em termos de fragmentação, chegando em torno de 15% da área reservada como heap;
- Baixo overhead de memória, necessita apenas de uma estrutura de controle no começo do heap;
- Política de alocação Good-Fit, garantindo um bloco de tamanho adequado com baixo desperdício de memória.
TLSF, como funciona?
O leitor mais curioso pode acessar a tese de doutorado inteira de Miguel Masmano. Do documento em questão vamos extrair os fundamentos de como o TLSF consegue atingir o tempo de execução constante (a principal variável em um sistema de tempo real). Masmano percebeu em outros alocadores baseados em listas segregadas, como o conhecido DLMalloc, que ele poderia acelerar a busca de um bloco de tamanho aceitável se subdividisse a região de heap em um grupo de listas de dois níveis, sendo o nível mais alto para os intervalos de tamanhos incrementais em potência de base 2, e o segundo nível como sendo blocos dentro de cada intervalo somado a um offset de 4 bytes (tamanho mínimo permitido na alocação) para cada bloco.
Esses blocos são acessíveis na forma de ponteiros e armazenados em um vetor bidimensional. Mas e aí, como acessar o bloco desejado em tempo de execução constante? Diferente de alocadores como o Binary Buddy e o DLMalloc, que possuem um loop de busca similar a uma busca binária para acessar os níveis e subníveis de suas listas segregadas, Masmano utilizou uma estratégia baseada na localização de posição de bits do tamanho do bloco requisitado. Assim como as listas segregadas estão ordenadas por potência de base 2 sabemos que cada bit em um word corresponde imediatamente a uma dessas potências. Então o gerenciador mapeia através do primeiro bit mais significativo colocado em 1 o tamanho de base do bloco. A posição desse bit será utilizada para mapear o primeiro nível da lista segregada. O segundo nível, menos elementar, é mapeado através de uma segunda aritmética de bits entre o primeiro nível, os bits menos significativos e uma terceira variável constante que trata da profundidade da lista segregada de segundo nível. Os dois resultados são combinados e concatenados, formando os pares de acesso ao vetor bidimensional de ponteiros e assim otendo-se o bloco livre (se houver) ou nulo, caso não haja mais espaço.
A liberação de um bloco de memória que não é mais necessário ocorre de forma similar, porém oculto ao bloco usado. Pode ser acessado o tamanho do bloco juntamente com endereço do bloco livre prévio. A partir do tamanho, é possível atualizar o mapa de bits da estrutura de controle do heap, e verificar se o bloco prévio é adjacente ao bloco que estamos liberando, permitindo realizar fusão e obter um bloco maior de memória livre (durante a alocação o inverso é feito caso o bloco obtido seja muito grande). Na figura abaixo podemos ver o que fisicamente é realizado na memória gerenciada:
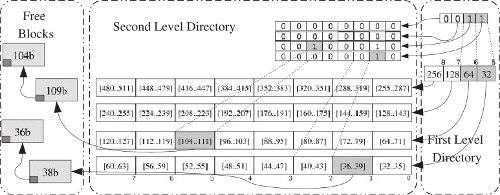
Eis o que acontece no heap, temos os dois níveis, vejam que o primeiro é bem separado nas potências de base 2, com ele acessamos primeiramente um segundo mapa de bits, onde contém blocos naquele intervalo somado algum offset em bytes. Uma vez que o bloco seja alocado, o mesmo é colocado em uma lista ligada segregada que aponta ao bloco prévio livre e guarda algumas informações sobre tamanho e uso. E quando desalocado, o mesmo é colocado de volta em sua lista com nível e subnível correspondente.
Implementando o gerenciador de memória TLSF
O documento com a tese de doutorado de Masmano descreve em detalhes, bem como o passo-a-passo para implementar as funções malloc() e free(). A função realloc(), até a escrita deste texto, não era suportada. O documento descreve as funções de busca e as operações de bits necessárias para mapear um bloco no heap. O pseudo-código encontra-se escrito em algo similar à linguagem Pascal, contudo esse gerenciador se tornou popular e acabou ganhando versões que vão, inclusive, embarcadas em distribuições do kenel Linux como Crux, patchs como o Xenomai e vários kernels de tempo real. Com isso implementações mais simples e mesmo em outras linguagens como o popular C, estão disponíveis a partir do trabalho de Masmano.
Esse que vos escreve implelementou uma versão do gerenciador TLSF para uso pessoal (que será embarcado no futuro RTOS que pretendo soltar ano que vem) mínima, apenas com as funções de alocação, liberação, inicialização e quantidade de bytes disponíveis no heap, sendo indicado pra quem quer colocar gerenciamento de memória naquele projetinho de final de semana com ARM, ou mesmo substituir o operador “new” e usar com seu Arduino. Lembrando que o valor mínimo de um bloco pode ser de 4 bytes e o tamanho máximo é limitado ao tamanho reservado para o heap (que pode ser feito via linker, ou estaticamente).
Abaixo temos o arquivo tlsf.c:
// // @file MemManager.c // @brief modulo gerenciador de memoria rapido e deterministico // para embedded, baseado no algoritmo TLSF de Miguel Masmano // // /* * Two Levels Segregate Fit memory allocator (TLSF) * Version 2.4.4 * * Written by Miguel Masmano Tello <[email protected]> * * Thanks to Ismael Ripoll for his suggestions and reviews * * Copyright (C) 2008, 2007, 2006, 2005, 2004 * * This code is released using a dual license strategy: GPL/LGPL * You can choose the licence that better fits your requirements. * * Released under the terms of the GNU General Public License Version 2.0 * Released under the terms of the GNU Lesser General Public License Version 2.1 * */ /* * Code contributions: * * (Jul 28 2007) Herman ten Brugge <[email protected]>: * * - Add 64 bit support. It now runs on x86_64 and solaris64. * - I also tested this on vxworks/32and solaris/32 and i386/32 processors. * - Remove assembly code. I could not measure any performance difference * on my core2 processor. This also makes the code more portable. * - Moved defines/typedefs from tlsf.h to tlsf.c * - Changed MIN_BLOCK_SIZE to sizeof (free_ptr_t) and BHDR_OVERHEAD to * (sizeof (bhdr_t) - MIN_BLOCK_SIZE). This does not change the fact * that the minumum size is still sizeof * (bhdr_t). * - Changed all C++ comment style to C style. (// -> /.* ... *./) * - Used ls_bit instead of ffs and ms_bit instead of fls. I did this to * avoid confusion with the standard ffs function which returns * different values. * - Created set_bit/clear_bit fuctions because they are not present * on x86_64. * - Added locking support + extra file target.h to show how to use it. * - Added get_used_size function (REMOVED in 2.4) * - Added rtl_realloc and rtl_calloc function * - Implemented realloc clever support. * - Added some test code in the example directory. * * * (Oct 23 2006) Adam Scislowicz: * * - Support for ARMv5 implemented * */ /* Code contributions: * (2015) Felipe Neves: * - added efficient ffs /fls based on armv7-m specifics * * */ #include <stdio.h> #include <string.h> #include "tlsf.h" // // Macros usadas para implementacado do sistema de estatistica: // #define TLSF_ADD_SIZE(tlsf, b) do { \ tlsf->used_size += (b->size & BLOCK_SIZE) + BHDR_OVERHEAD; \ if (tlsf->used_size > tlsf->max_size) \ tlsf->max_size = tlsf->used_size; \ } while(0) #define TLSF_REMOVE_SIZE(tlsf, b) do { \ tlsf->used_size -= (b->size & BLOCK_SIZE) + BHDR_OVERHEAD; \ } while(0) // // Macros e definicoes da estrutura do TFSL // #define BLOCK_ALIGN (sizeof(void *) * 2) //Alinhamento minimo de bloco (tamanho minimo de 4bytes) #define MAX_FLI (30) #define MAX_LOG2_SLI (5) #define MAX_SLI (1 << MAX_LOG2_SLI) //Calculador de posicoes maximas dos bitmaps #define FLI_OFFSET (6) //Profundidade do bitmap de primeiro nivel #define SMALL_BLOCK (128) #define REAL_FLI (MAX_FLI - FLI_OFFSET) #define MIN_BLOCK_SIZE (sizeof (free_ptr_t)) #define BHDR_OVERHEAD (sizeof (bhdr_t) - MIN_BLOCK_SIZE) #define TLSF_SIGNATURE (0x2A59FA59) #define PTR_MASK (sizeof(void *) - 1) #define BLOCK_SIZE (0xFFFFFFFF - PTR_MASK) #define GET_NEXT_BLOCK(_addr, _r) ((bhdr_t *) ((uint8_t *) (_addr) + (_r))) #define MEM_ALIGN ((BLOCK_ALIGN) - 1) #define ROUNDUP_SIZE(_r) (((_r) + MEM_ALIGN) & ~MEM_ALIGN) #define ROUNDDOWN_SIZE(_r) ((_r) & ~MEM_ALIGN) #define ROUNDUP(_x, _v) ((((~(_x)) + 1) & ((_v)-1)) + (_x)) // // Estados dos blocos de memoria // #define BLOCK_STATE (0x1) #define PREV_STATE (0x2) #define FREE_BLOCK (0x1) #define USED_BLOCK (0x0) #define PREV_FREE (0x2) #define PREV_USED (0x0) // // Area size se utilizado com SBRK: // #define DEFAULT_AREA_SIZE (1024*10) // // Log & asserts: // #define PRINT_MSG(fmt, args...) printf(fmt, ## args) #define ERROR_MSG(fmt, args...) printf(fmt, ## args) // // Heap linked list cast: // typedef struct free_ptr_struct { struct bhdr_struct *prev; struct bhdr_struct *next; } free_ptr_t; // // TFSL block header: // typedef struct bhdr_struct { struct bhdr_struct *prev_hdr; size_t size; union { struct free_ptr_struct free_ptr; uint8_t buffer[1]; } ptr; }bhdr_t; // // Area info: // typedef struct area_info_struct { bhdr_t *end; struct area_info_struct *next; } area_info_t; // // Estrutura TFSL completa aresponsavel por gerenciar o heap: // typedef struct TLSF_struct { uint32_t tlsf_signature; size_t used_size; size_t max_size; area_info_t *area_head; // // Bitmap de acesso aos blocos: // uint32_t fl_bitmap; uint32_t sl_bitmap[REAL_FLI]; // // Matrix de ponteiros para a linked buddy list: // bhdr_t *matrix[REAL_FLI][MAX_SLI]; } tlsf_t; // // mecanismo de Thread safe // // // Forward references de funcoes internas para busca de blocos: // static __inline void set_bit(int32_t nr, uint32_t * addr); static __inline void clear_bit(int32_t nr, uint32_t * addr); static __inline int32_t ls_bit(int32_t x); static __inline int32_t ms_bit(int32_t x); static __inline void MAPPING_SEARCH(size_t * _r, int32_t *_fl, int32_t *_sl); static __inline void MAPPING_INSERT(size_t _r, int32_t *_fl, int32_t *_sl); static __inline bhdr_t *FIND_SUITABLE_BLOCK(tlsf_t * _tlsf, int32_t *_fl, int32_t *_sl); static __inline bhdr_t *process_area(void *area, size_t size); static size_t init_memory_pool(size_t mem_pool_size, void *mem_pool); static size_t add_new_area(void *area, size_t area_size, void *mem_pool); static size_t get_used_size(void *mem_pool); static size_t get_max_size(void *mem_pool); static void destroy_memory_pool(void *mem_pool); static void *malloc_ex(size_t size, void *mem_pool); static void free_ex(void *ptr, void *mem_pool); // // ls_bit() // static __inline int32_t ls_bit(int32_t i) { //Usa a funcao otimizada contida em bitman.c: return(fls(i)); } // // ms_bit(): // static __inline int32_t ms_bit(int32_t i) { //usa funcao otimizada contida em bitman.c return(ffs(i)); } // // set_bit() // static __inline void set_bit(int32_t nr, uint32_t * addr) { addr[nr >> 5] |= 1 << (nr & 0x1f); } // // clear bit: // static __inline void clear_bit(int32_t nr, uint32_t * addr) { addr[nr >> 5] &= ~(1 << (nr & 0x1f)); } // // MAPPING_SEARCH() // static __inline void MAPPING_SEARCH(size_t * _r, int32_t *_fl, int32_t *_sl) { int32_t _t; // // Esse helper tem por funcao a partir do tamanho do bloco // de memoria desejado, mapear via um bitmap de dois niveis // a buddy list que pode conter o bloco de tamanho adequado: // if (*_r < SMALL_BLOCK) { *_fl = 0; *_sl = *_r / (SMALL_BLOCK / MAX_SLI); } else { _t = (1 << (ms_bit(*_r) - MAX_LOG2_SLI)) - 1; *_r = *_r + _t; *_fl = ms_bit(*_r); *_sl = (*_r >> (*_fl - MAX_LOG2_SLI)) - MAX_SLI; *_fl -= FLI_OFFSET; *_r &= ~_t; } } // // MAPPING_INSERT: // static __inline void MAPPING_INSERT(size_t _r, int32_t *_fl, int32_t *_sl) { // // De forma similar ao search, o mapping insert // em funcao do tamanho do bloco passado (em um free) // mapeia a buddy list (atraves dos bitmaps) para saber // a posicao nesta em qual o blcoo deve ser devolvido. if (_r < SMALL_BLOCK) { *_fl = 0; *_sl = _r / (SMALL_BLOCK / MAX_SLI); } else { *_fl = ms_bit(_r); *_sl = (_r >> (*_fl - MAX_LOG2_SLI)) - MAX_SLI; *_fl -= FLI_OFFSET; } } // // FIND_SUITABLE_BLOCK() // static __inline bhdr_t *FIND_SUITABLE_BLOCK(tlsf_t * _tlsf, int32_t *_fl, int32_t *_sl) { uint32_t _tmp = _tlsf->sl_bitmap[*_fl] & (~0 << *_sl); bhdr_t *_b = NULL; // // A partir das posicoes do bitmap obtidas executa a estrategia // de good fit para pegar da buddylist o melhor bloco para o size // desejado conforme a politica do good fit: if (_tmp) { *_sl = ls_bit(_tmp); _b = _tlsf->matrix[*_fl][*_sl]; } else { *_fl = ls_bit(_tlsf->fl_bitmap & (~0 << (*_fl + 1))); if (*_fl > 0) { *_sl = ls_bit(_tlsf->sl_bitmap[*_fl]); _b = _tlsf->matrix[*_fl][*_sl]; } } return _b; } // // Remove o block header do stream de memoria obtido: // #define EXTRACT_BLOCK_HDR(_b, _tlsf, _fl, _sl) do { \ _tlsf -> matrix [_fl] [_sl] = _b -> ptr.free_ptr.next; \ if (_tlsf -> matrix[_fl][_sl]) \ _tlsf -> matrix[_fl][_sl] -> ptr.free_ptr.prev = NULL; \ else { \ clear_bit (_sl, &_tlsf -> sl_bitmap [_fl]); \ if (!_tlsf -> sl_bitmap [_fl]) \ clear_bit (_fl, &_tlsf -> fl_bitmap); \ } \ _b -> ptr.free_ptr.prev = NULL; \ _b -> ptr.free_ptr.next = NULL; \ }while(0) // // Faz unlink do bloco de memoria da buddy list: // #define EXTRACT_BLOCK(_b, _tlsf, _fl, _sl) do { \ if (_b -> ptr.free_ptr.next) \ _b -> ptr.free_ptr.next -> ptr.free_ptr.prev = _b -> ptr.free_ptr.prev; \ if (_b -> ptr.free_ptr.prev) \ _b -> ptr.free_ptr.prev -> ptr.free_ptr.next = _b -> ptr.free_ptr.next; \ if (_tlsf -> matrix [_fl][_sl] == _b) { \ _tlsf -> matrix [_fl][_sl] = _b -> ptr.free_ptr.next; \ if (!_tlsf -> matrix [_fl][_sl]) { \ clear_bit (_sl, &_tlsf -> sl_bitmap[_fl]); \ if (!_tlsf -> sl_bitmap [_fl]) \ clear_bit (_fl, &_tlsf -> fl_bitmap); \ } \ } \ _b -> ptr.free_ptr.prev = NULL; \ _b -> ptr.free_ptr.next = NULL; \ } while(0) // // efetua o link (ou re-link) de um bloco de memoria na buddy list: // #define INSERT_BLOCK(_b, _tlsf, _fl, _sl) do { \ _b -> ptr.free_ptr.prev = NULL; \ _b -> ptr.free_ptr.next = _tlsf -> matrix [_fl][_sl]; \ if (_tlsf -> matrix [_fl][_sl]) \ _tlsf -> matrix [_fl][_sl] -> ptr.free_ptr.prev = _b; \ _tlsf -> matrix [_fl][_sl] = _b; \ set_bit (_sl, &_tlsf -> sl_bitmap [_fl]); \ set_bit (_fl, &_tlsf -> fl_bitmap); \ } while(0) // // get_new_area() // static __inline void *get_new_area(size_t * size) { return ((void *) ~0); } // // process_area() // static __inline bhdr_t *process_area(void *area, size_t size) { bhdr_t *b, *lb, *ib; area_info_t *ai; ib = (bhdr_t *) area; ib->size = (sizeof(area_info_t) < MIN_BLOCK_SIZE) ? MIN_BLOCK_SIZE : ROUNDUP_SIZE(sizeof(area_info_t)) | USED_BLOCK | PREV_USED; b = (bhdr_t *) GET_NEXT_BLOCK(ib->ptr.buffer, ib->size & BLOCK_SIZE); b->size = ROUNDDOWN_SIZE(size - 3 * BHDR_OVERHEAD - (ib->size & BLOCK_SIZE)) | USED_BLOCK | PREV_USED; b->ptr.free_ptr.prev = b->ptr.free_ptr.next = 0; lb = GET_NEXT_BLOCK(b->ptr.buffer, b->size & BLOCK_SIZE); lb->prev_hdr = b; lb->size = 0 | USED_BLOCK | PREV_FREE; ai = (area_info_t *) ib->ptr.buffer; ai->next = 0; ai->end = lb; return ib; } // // Funcoes high level do alocador de memoria: // static uint8_t *mp = NULL; //Memory pool default. // // init_memory_pool(): // size_t init_memory_pool(size_t mem_pool_size, void *mem_pool) { tlsf_t *tlsf; bhdr_t *b, *ib; // // Checa consistencia do ponteiro da pool: // if (!mem_pool || !mem_pool_size || mem_pool_size < sizeof(tlsf_t) + BHDR_OVERHEAD * 8) { ERROR_MSG("init_memory_pool (): memory_pool invalid\n"); return -1; } // // Checa se o alinhamento da pool esta correto, // deve estar alinhado em pelomenos 4bytes: if (((unsigned long) mem_pool & PTR_MASK)) { ERROR_MSG("init_memory_pool (): mem_pool must be aligned to a word\n"); return -1; } // // Mapeia no formato da estrutura tfsl: // tlsf = (tlsf_t *) mem_pool; // // Checa se ja foi inicializada: // if (tlsf->tlsf_signature == TLSF_SIGNATURE) { mp = mem_pool; b = GET_NEXT_BLOCK(mp, ROUNDUP_SIZE(sizeof(tlsf_t))); return b->size & BLOCK_SIZE; } // // Faz o default mp apontar pra \B4pool: // mp = mem_pool; // // Faz zero fill da pool, usa a funcao otimizada contida em optmem.s // optMemSet(mem_pool, 0, sizeof(tlsf_t)); // // Inicializa o mapa de memoria da pool: // tlsf->tlsf_signature = TLSF_SIGNATURE; ib = process_area(GET_NEXT_BLOCK (mem_pool, ROUNDUP_SIZE(sizeof(tlsf_t))), ROUNDDOWN_SIZE(mem_pool_size - sizeof(tlsf_t))); b = GET_NEXT_BLOCK(ib->ptr.buffer, ib->size & BLOCK_SIZE); free_ex(b->ptr.buffer, tlsf); tlsf->area_head = (area_info_t *) ib->ptr.buffer; // // Inicializa sistema de estatistica da pool: // tlsf->used_size = mem_pool_size - (b->size & BLOCK_SIZE); tlsf->max_size = tlsf->used_size; return (b->size & BLOCK_SIZE); } // // add_new_area() // size_t add_new_area(void *area, size_t area_size, void *mem_pool) { tlsf_t *tlsf = (tlsf_t *) mem_pool; area_info_t *ptr, *ptr_prev, *ai; bhdr_t *ib0, *b0, *lb0, *ib1, *b1, *lb1, *next_b; memset(area, 0, area_size); ptr = tlsf->area_head; ptr_prev = 0; ib0 = process_area(area, area_size); b0 = GET_NEXT_BLOCK(ib0->ptr.buffer, ib0->size & BLOCK_SIZE); lb0 = GET_NEXT_BLOCK(b0->ptr.buffer, b0->size & BLOCK_SIZE); while (ptr) { ib1 = (bhdr_t *) ((uint8_t *) ptr - BHDR_OVERHEAD); b1 = GET_NEXT_BLOCK(ib1->ptr.buffer, ib1->size & BLOCK_SIZE); lb1 = ptr->end; if ((unsigned long) ib1 == (unsigned long) lb0 + BHDR_OVERHEAD) { if (tlsf->area_head == ptr) { tlsf->area_head = ptr->next; ptr = ptr->next; } else { ptr_prev->next = ptr->next; ptr = ptr->next; } b0->size = ROUNDDOWN_SIZE((b0->size & BLOCK_SIZE) + (ib1->size & BLOCK_SIZE) + 2 * BHDR_OVERHEAD) | USED_BLOCK | PREV_USED; b1->prev_hdr = b0; lb0 = lb1; continue; } if ((unsigned long) lb1->ptr.buffer == (unsigned long) ib0) { if (tlsf->area_head == ptr) { tlsf->area_head = ptr->next; ptr = ptr->next; } else { ptr_prev->next = ptr->next; ptr = ptr->next; } lb1->size = ROUNDDOWN_SIZE((b0->size & BLOCK_SIZE) + (ib0->size & BLOCK_SIZE) + 2 * BHDR_OVERHEAD) | USED_BLOCK | (lb1->size & PREV_STATE); next_b = GET_NEXT_BLOCK(lb1->ptr.buffer, lb1->size & BLOCK_SIZE); next_b->prev_hdr = lb1; b0 = lb1; ib0 = ib1; continue; } ptr_prev = ptr; ptr = ptr->next; } ai = (area_info_t *) ib0->ptr.buffer; ai->next = tlsf->area_head; ai->end = lb0; tlsf->area_head = ai; free_ex(b0->ptr.buffer, mem_pool); return (b0->size & BLOCK_SIZE); } // // get_used_size() // size_t get_used_size(void *mem_pool) { // // pega a quantidade de memoria consumida // da pool via acesso direto a info: // return ((tlsf_t *) mem_pool)->used_size; } // // get_max_size() // size_t get_max_size(void *mem_pool) { // // de forma similar ao get_size o max-size // retorna o tamanho do maior bloco que da pra pegar // da pool: return ((tlsf_t *) mem_pool)->max_size; } // // destroy_memory_pool() // void destroy_memory_pool(void *mem_pool) { // // para destruir a pool (em nossa aplicacao nao usado) // busca a mesma e apenas elimina a signature: // tlsf_t *tlsf = (tlsf_t *) mem_pool; tlsf->tlsf_signature = 0; } // // malloc_ex() // void *malloc_ex(size_t size, void *mem_pool) { // // implementacao baixo nivel do alloc: // tlsf_t *tlsf = (tlsf_t *) mem_pool; bhdr_t *b, *b2, *next_b; int32_t fl, sl; size_t tmp_size; //checagem e round de tamanho: size = (size < MIN_BLOCK_SIZE) ? MIN_BLOCK_SIZE : ROUNDUP_SIZE(size); //Busca os bit positions: MAPPING_SEARCH(&size, &fl, &sl); //Busca o bloco usando o good fit strategy b = FIND_SUITABLE_BLOCK(tlsf, &fl, &sl); //Nao achou bloco? Retorna 0 if (b == 0) return NULL; //extrai o header EXTRACT_BLOCK_HDR(b, tlsf, fl, sl); //faz o tfsl apontar ao proximo blloco livre dessa buddy list next_b = GET_NEXT_BLOCK(b->ptr.buffer, b->size & BLOCK_SIZE); tmp_size = (b->size & BLOCK_SIZE) - size; if (tmp_size >= sizeof(bhdr_t)) { // // se o bloco for muito grande, faz split // tmp_size -= BHDR_OVERHEAD; b2 = GET_NEXT_BLOCK(b->ptr.buffer, size); b2->size = tmp_size | FREE_BLOCK | PREV_USED; next_b->prev_hdr = b2; MAPPING_INSERT(tmp_size, &fl, &sl); INSERT_BLOCK(b2, tlsf, fl, sl); b->size = size | (b->size & PREV_STATE); } else { next_b->size &= (~PREV_FREE); b->size &= (~FREE_BLOCK); } // // atualiza a estatistica da pool // TLSF_ADD_SIZE(tlsf, b); //bloco pronto pra uso: return (void *) b->ptr.buffer; } // // free_ex() // void free_ex(void *ptr, void *mem_pool) { tlsf_t *tlsf = (tlsf_t *) mem_pool; bhdr_t *b, *tmp_b; int32_t fl = 0, sl = 0; //bloco invalido? nao realiza acao if (!ptr) return; b = (bhdr_t *) ((uint8_t *) ptr - BHDR_OVERHEAD); b->size |= FREE_BLOCK; TLSF_REMOVE_SIZE(tlsf, b); b->ptr.free_ptr.prev = NULL; b->ptr.free_ptr.next = NULL; // // Pega o proximo bloco lire do buddy list // tmp_b = GET_NEXT_BLOCK(b->ptr.buffer, b->size & BLOCK_SIZE); // //se os blocos adjacentes estiverem livres //e fizerem parte do mesmo buddy list //efetua a fusao destes em um unico //bloco maior if (tmp_b->size & FREE_BLOCK) { MAPPING_INSERT(tmp_b->size & BLOCK_SIZE, &fl, &sl); EXTRACT_BLOCK(tmp_b, tlsf, fl, sl); b->size += (tmp_b->size & BLOCK_SIZE) + BHDR_OVERHEAD; } if (b->size & PREV_FREE) { tmp_b = b->prev_hdr; MAPPING_INSERT(tmp_b->size & BLOCK_SIZE, &fl, &sl); EXTRACT_BLOCK(tmp_b, tlsf, fl, sl); tmp_b->size += (b->size & BLOCK_SIZE) + BHDR_OVERHEAD; b = tmp_b; } // // Devolve o bloco ao buddylist // MAPPING_INSERT(b->size & BLOCK_SIZE, &fl, &sl); INSERT_BLOCK(b, tlsf, fl, sl); // // atualiza buddylist para proxima posicao livre nesse bloco // tmp_b = GET_NEXT_BLOCK(b->ptr.buffer, b->size & BLOCK_SIZE); tmp_b->size |= PREV_FREE; tmp_b->prev_hdr = b; } // //Funcoes publicas: // // // HeapInit() // void HeapInit(uint8_t *heapp, uint32_t heapSize) { int32_t size = 0; // // checa se o heap eh valido: // if(heapp == 0) { // // Mata o sistema de lock e nao inicializa // return; } // // Pede ao alocator pra preparar o heap: // size = init_memory_pool(heapSize, heapp); if(size == 0) { return; } //Inicializou corretamente, heap pronto para uso. } // // uMalloc() // void *uMalloc(uint32_t size) { void *p = NULL; // // Limita o size do bloco: // if(size > 16384) size = 16000; // // Acessa o alocador em safe mode // p = malloc_ex(size, mp); return(p); } // // uFree() // void uFree(void *p) { // // checa consistencia do bloco: // if(p == NULL) return; free_ex(p, mp); } // // uGetAvailable() // uint32_t uGetAvailable(void) { if(mp != NULL) { return(get_max_size(mp) - get_used_size(mp)); } else { return 0; } }
Nesse arquivo temos o ponto onde a mágica ocorre, as funções do algoritmo implementado pelo autor original bem como algumas macros para facilitar a inserção e retirada de blocos. As funções públicas estão ao final e permitem a implementação de mecanismos de sincronização como Mutex ou Semáforos ao acessar o heap. Abaixo temos tlsf.h:
// // @file utils.h // @brief Coletanea de support code util deve ser // colocada aqui. // // #ifndef __TLSF_H #define __TLSF_H #include <stdint.h> // @fn ffs() // @brief retorna o numero do bit onde aparece o // set mais significativo uint32_t ffs(uint32_t word); // // @fn fls() // @brief retorna o numero do bit onde aparece o // set menos significativo uint32_t fls(uint32_t word); // // @fn HeapInit() // @brief Inicializa um Heap para usar como pool de memoria // void HeapInit(uint8_t *heapp,uint32_t heapSize); // // @fn uMalloc() // @brief Aloca um bloco de memoria // void *uMalloc(uint32_t size); // // @fn uFree() // @brief Destroi um bloco de memoria previamente // Alocado void uFree(void *p); // // @fn uGetAvailable() // @brief toma o espaco corrente do manager // uint32_t uGetAvailable(void); #endif
Esse arquivo é o famoso “glue module”, ou seja, pega todas as funções que podem tornar-se públicas, e junta tudo num único lugar, bastando o usuário incluir esse arquivo no seu projeto que estará apto a utilizar o gerenciador de memória. Logo abaixo temos o arquivo bits.c:
#include "tlsf.h"
extern uint32_t CntLeadZeros(uint32_t word);
extern uint32_t CntTrailZeros(uint32_t word);
//
// ffs()
//
uint32_t uffs(uint32_t word)
{
//
// Adiciona o offset de delimitacao de word ao parametro
// e usa o hardware do ARM para buscar o bit:
//
return( BIT_WORD_SIZE - CntLeadZeros(word));
}
//
// fls()
//
uint32_t ufls(uint32_t word)
{
//
// Assim basta aplicar a mesma metodologia do ffs:
//
return(BIT_WORD_SIZE - CntTrailZeros(word));
}
Esse é uma interface para as funções de posição de bits, seu objetivo é apenas servir como camada de abstração caso o desenvolvedor queira implementar versões otimizadas dessas funções, utilizando o hardware do processador para isso. No caso da implementação, isso foi feito gerando o arquivo bits_a.S abaixo:
@ @ @ @file TraillingZeros.s @ @brief Funcao para busca do bit menos significativo setado @ @ @ .section .text .thumb .globl CntTrailZeros .globl CntLeadZeros @ @ CntTrailZeros() @ CntTrailZeros: rbit r0,r0 @ Change MSB with LSB position. clz r0,r0 @ use clz to find the "fake" MSB set bx lr @ em 1 do novo word. @ @ CntLeadZeros() @ CntLeadZeros: clz r0,r0 @ bx lr @ .end
Não torça o nariz pro código Assembly, caro leitor. Ele é auto-explicativo, apenas foram aproveitadas duas instruções por hardware do processador (no caso um ARMv7-M) para fazer a busca de bits de forma rápida. Mas caso não seja o seu caso, você pode implementar dentro de bits.c seu próprio algoritmo de posição de bits, vejam aqui.
E abaixo, temos uma pequena forma de como tal código pode ser utilizado, se o leitor tiver um ambiente previamente montado com o QEMU configurável é possível ver esse trecho de código em ação:
/*
============================================================================
Name : main.c
Author :
Version :
Copyright :
Description : Hello World in C
============================================================================
*/
#include <stdio.h>
/*
*
* Print a greeting message on standard output and exit.
*
* On embedded platforms this might require semi-hosting or similar.
*
* For example, for toolchains derived from GNU Tools for Embedded,
* to enable semi-hosting, the following was added to the linker:
*
* --specs=rdimon.specs -Wl,--start-group -lgcc -lc -lc -lm -lrdimon -Wl,--end-group
*
* Adjust it for other toolchains.
*
*/
#include <stdio.h>
#include "tlsf.h"
static uint8_t heap [8192];
int main(void)
{
int *p = 0;
int s = 0;
HeapInit(&heap, sizeof(heap));
s= uGetAvailable();
printf("Heap alocado em bytes: %d \n\r",s);
p = uMalloc(1024);
s= uGetAvailable();
printf("Heap livre em bytes: %d \n\r",s);
for(;;);
return 0;
}
Descrevendo rapidamente, a função HeapInit() é responsável por receber e inicializar uma área de memória para ser usada com o TLSF, lembre-se que diferentemente do exemplo, que a área de memória está reservada de forma estática. Podemos fazer com que isso seja transparente à aplicação, criando um .section correspondente no arquivo de ligação (os famosos .ld usados pelo Linker), as demais linhas são auto-explicativas, com impressão de strings no console (dai o uso do QEMU, zero necessidade de configurar o stdout) para ver o estado do heap antes e depois da alocação de memória.
Conclusão
Ok, sabemos que mesmo com um gerenciador como o TLSF, que possui execução em termo de tempo constante, tendo baixo overhead e magnitude de fragmentação, todo e qualquer gerenciador de memória deve ser usado com cautela, estando grande parte dela a cargo do programador. Pois sem as devidas providências de segurança e prevenção de acesso múltiplo ao heap o resultado pode ser frustrante, fazendo o leitor acabar mais cedo lendo o artigo sobre debug de hardfault. Mas se bem utilizado, um módulo que reserva e desaloca memória em tempo de execução, pode ser bem poderoso sendo útil em casos onde o Arduino é utilizado, pensem na possibilidade de substituir o operador “new” por uma forma rápida e real time de pegar memória do sistema para implementar objetos dos mais variados tipos e com máxima flexibilidade. E você leitor, o que acha dessa opção? Até a próxima.
Referências
MASMANO, Miguel – Gestion de Memoria Dinámica em Sistemas de Tiempo Real, 2007














Parabéns pelo artigo!
Já tem algum tempo que eu estou tentando iniciar este tipo de aplicação para embarcados mas sempre senti falta de algo concreto para começar estudar.
Muito esclarecedor!
Ótimo artigo Felipe!
Primeiramente, parabéns pela implementação. Ela realmente é muito complexa! Estou tentando executar o TLFS que você disponibilizou para avaliar desempenho, fragmentação, etc. Mas tive dois problemas. A primeira é que não possuo a função ‘optMemSet’, o que ela faz é inicializar o array com zeros, eu poderia fazer assim? “int array[i] = { 0 }”. A outra questão, não sei se foi problema do optMemSet, mas enfim, ocorre problema na inicialização do heap, especificamente na macro “INSERT_BLOCK”, o erro é a que segue: “Exception thrown at 0x000320C3 in c.exe: 0xC0000005: Access violation writing location 0x0003AFAC.” Para conseguir ver exatamente em… Leia mais »