
Introdução
Um sistema de alta disponibilidade ideal é aquele que permanece ativo e funcionando continuamente, sem interrupções, por um período de tempo indefinido. Em termos práticos, estes sistemas geralmente buscam uma disponibilidade de cinco noves, uma métrica que se refere à porcentagem de tempo de atividade que um sistema pode sustentar em um ano; 99,999% de tempo de atividade equivale a cerca de cinco minutos de tempo de inatividade por ano.
Para alcançar essa alta disponibilidade, diversas estratégias e tecnologias são implementadas. Entre elas, destacam-se a redundância de elementos críticos desde o hardware até o firmware/software e monitoramento contínuo para detectar e corrigir problemas antes que eles causem interrupções no serviço.
Além da redundância e do monitoramento, a arquitetura de software de um sistema de alta disponibilidade deve ser projetada para ser tolerante a falhas. Isso inclui a implementação de algoritmos de recuperação automática e a capacidade de realizar atualizações e manutenções sem interromper o serviço.
Obviamente, os sistemas falham!
No contexto de sistemas embarcados, as falhas podem ocorrer devido a uma variedade de razões.
Hardware
- Desgaste: Componentes eletrônicos, podem falhar com o tempo devido ao desgaste natural.
- Sobrecarga: Exposição a níveis de tensão ou corrente acima do especificado pode danificar ou degradar componentes.
- Defeitos de fabricação: Componentes defeituosos ou mal soldados podem causar falhas intermitentes ou permanentes.
- Interferência eletromagnética (EMI): Pode causar mau funcionamento de circuitos sensíveis.
- Falhas de energia: Alimentação inadequada, quedas ou picos de energia podem danificar componentes ou causar reinicializações inesperadas.
Software
- Bugs ou erros de lógica: Erros de programação podem levar a comportamentos inesperados.
- Condições de corrida: Quando dois processos tentam acessar um recurso compartilhado ao mesmo tempo, pode ocorrer um comportamento não determinístico.
- Problemas de memória: Erros como vazamentos ou corrupção de memória.
Fatores ambientais e humanos
- Temperaturas: Temperaturas muito altas ou muito baixas podem afetar o desempenho e a confiabilidade dos componentes.
- Umidade: Pode causar corrosão ou curtos-circuitos nos componentes eletrônicos.
- Vibração e choque: Podem causar danos físicos aos componentes ou conexões.
- Erros de instalação, manutenção ou operação: Instalação incorreta, manutenção inadequada ou erros ao interagir com o sistema.
Ataques de segurança
- Ataques cibernéticos: Sistemas embarcados podem ser vulneráveis a ataques que exploram falhas de segurança no software ou no hardware.
- Inserção de código malicioso: Malwares podem causar comportamentos indesejados ou danificar o sistema.
Por uma razão ou outra, os sistemas não estão tão disponíveis quanto seus usuários e projetistas gostariam que estivessem. De todas as possíveis causas de falhas do sistema, provavelmente a maior parte tem alguma origem nas falhas de software.
Muitos sistemas tentam mitigar problemas utilizando componentes de hardware mais robustos e tolerantes a falhas e redundâncias em elementos críticos.
Mas se tantas falhas de sistema são causadas por falhas de software, será que apenas usar mais hardware resolve o problema?
Abordagens para “garantir” alta disponibilidade (a “solução” do reset)
Em muitos sistemas o único mecanismo de recuperação seguro é reiniciar tudo e começar do zero!
Nesta abordagem, o planejamento e tratamento de falhas é muito simples, requer apenas uma reinicialização completa do sistema.
A abordagem tradicional envolve o uso de Watchdog Timer, um mecanismo de segurança utilizado em sistemas embarcados para monitorar seu funcionamento e reiniciá-lo se ele falhar.
Basicamente, um watchdog é um periférico de um microcontrolador, ou componente externo de hardware, funcionando como um temporizador que precisa ser reiniciado constantemente antes que seu tempo configurado expire. Se isto acontecer, ele vai provocar o reset do sistema.
O firmware precisa ser planejado para enviar estes comandos de “refresh” periodicamente ao watchdog comprovando que ele permanece em funcionamento normal. Se o sistema “travar”, o temporizador expira!
Em alguns sistemas, no entanto, isso pode ser inviável, quando é crítico tempo que o sistema fica inativo até sua restauração completa.
Para algumas aplicações, uma reinicialização pode envolver um procedimento em etapas e demorado para restaurar o sistema.
Abordagens de software
As abordagens tradicionais para lidar com falhas no software envolvem uma combinação de técnicas preventivas, corretivas e de recuperação.
Testes unitários, integração e aceitação, gerenciamento de configuração, redundância de software e tolerância a falhas para processos críticos, depuração, logging, monitoramento contínuo, entre outros.
Um bom planejamento e ampla análise de falhas é essencial para minimizar falhas, mas ainda assim elas podem ocorrer.
Alta disponibilidade inerente do QNX
Segundo a documentação do QNX, se considerarmos só a sua arquitetura microkernel, já podemos encontrar muitos elementos para um sistema de alta disponibilidade.
O microkernel fornece estabilidade para todo o sistema, oferecendo proteção total de memória para todos os processos.
O núcleo oferece apenas serviços essenciais como o gerenciamento de memória, escalonamento e comunicação entre processos (IPC).
Cada processo de usuário e device driver é executado em espaço isolado e fora do núcleo. Você pode iniciar ou parar um driver, protocolo de rede, sistema de arquivos, a qualquer momento e sem tocar no kernel.
Além disso, se por algum motivo, qualquer um desses processos se tornar inoperante, esta falha afetará apenas ele, mantendo o restante do sistema intacto.
High Availability Manager (HAM)
Além de sua arquitetura inerentemente robusta, o QNX OS também fornece um Gerenciador de Alta Disponibilidade – Trata-se de um mecanismo completo e inteligente que monitora processos críticos do sistema e executa ações de recuperação em caso de falhas.
O objetivo é fornecer um gerenciador resiliente (ou “smart watchdog“) que possa realizar recuperação em vários estágios sempre que os serviços ou processos do sistema falharem, não responderem mais ou forem detectados em um estado em que deixam de fornecer níveis aceitáveis de serviço.
Por exemplo, suponha que um driver de dispositivo trave porque tentou gravar na memória alocada para outro processo. A MMU alertará o microkernel, que por sua vez alertará o High Availability Manager (HAM) que pode então reiniciar o driver. Simples assim!
Além disso, um arquivo de despejo pode ser gerado para análise postmortem. Analisando esse arquivo de despejo, você pode determinar o motivo da falha e então preparar uma correção.
Uma funcionalidade bastante útil presente neste mecanismo é a possibilidade de realizar uma recuperação em vários estágios, executando diversas ações em uma determinada ordem. Isto é útil quando existem dependências entre várias ações em uma sequência, para que o sistema possa restaurar-se ao estado em que estava antes da falha.
Para iniciar o HAM basta executar o utilitário “ham” e a partir deste momento ele vai monitorar os processos (entities) anexados a ele e então, disparar ações de recuperação (actions) caso ocorra alguma falha nestes processos.
hamQuando o HAM é iniciado, ele também inicia o processo do Guardian (veja a seguir).
O HAM e o Guardião
Como já dissemos, o High Availability Manager (HAM) monitora processos e serviços em seu sistema e dispara uma série de ações para possibilitar a recuperação do sistema em caso de falhas.
Para tornar o mecanismo de alta disponibilidade do QNX ainda mais robusto, um processo espelho chamado Guardian é criado juntamente com o HAM. Ele é responsável para assumir o papel do HAM caso ele próprio seja interrompido de forma anormal por algum motivo, retornando ao seu estado original de contínuo monitoramento.
Esta redundância HAM/Guardian faz com que um monitore ao outro, e a falha de qualquer um deles pode ser completamente recuperada. A única maneira de parar o HAM é instruí-lo explicitamente para encerrar o Guardian e depois encerrar a si mesmo.
Hierarquia do HAM
Entidades
As entidades são as unidades fundamentais de observação e monitoramento do sistema. Essencialmente, uma entidade é um processo identificável pelo seu pid (process id).
As entidades podem ser do tipo Self-attached, Externally attached e Global. Consulte a documentação para entender melhor suas diferenças e onde são utilizadas.
Condições
As condições representam o estado de uma entidade. Aqui estão alguns exemplos de condições:
| Condição | Descrição |
| CONDADETH | A entidade morreu. |
| CONDABNORMALDEATH | A entidade teve uma morte anormal. Sempre que uma entidade morre, esta condição é acionada por um mecanismo que resulta na geração de um arquivo de core dump. |
| CONDDETACH | A entidade que estava sendo monitorada está sendo desvinculada. Isto encerra o monitoramento daquela entidade pelo HAM. |
| CONDATACAR | Uma entidade para a qual um espaço reservado foi criado anteriormente (ou seja, algum processo subscreveu eventos relacionados a esta entidade) aderiu ao sistema. Este é também o início do monitoramento da entidade pelo HAM. |
| CONDHBEATMISSEDHIGH | A entidade deixou de enviar uma mensagem de pulsação especificada para uma condição de alta gravidade. |
| CONDHBEATMISSEDLOW | A entidade perdeu o envio de uma mensagem de pulsação especificada para uma condição low . |
| CONDRESTART | A entidade foi reiniciada. Esta condição é verdadeira depois que a entidade é reiniciada com sucesso. |
| CONDRAISE | Uma condição detectada externamente é reportada ao HAM. Os assinantes podem associar ações a essas condições detectadas externamente. |
| CONDSTATO | Uma entidade relata uma transição de estado para o HAM. Os assinantes podem associar ações a transições de estado específicas. |
| CONDANY | Este tipo de condição corresponde a qualquer tipo de condição. Pode ser usado para associar as mesmas ações a uma dentre muitas condições. |
Ações
As ações estão associadas às condições e são executadas sempre que a condição correspondente for verdadeira. Uma condição pode conter diversas ações.
A API HAM inclui diversas funções para diferentes tipos de ações:
| Ação | Descrição |
| ham_action_restart() | Esta ação reinicia a entidade |
| ham_action_execute() | Executa um comando arbitrário (por exemplo, para iniciar um processo) |
| ham_action_notify_pulse() | Notifica algum processo de que esta condição ocorreu. Esta notificação é enviada através de um pulso específico com valor especificado pelo processo que deseja receber esta mensagem de notificação. |
| ham_action_notify_signal() | Notifica algum processo de que esta condição ocorreu. Esta notificação é enviada através de um sinal específico em tempo real com um valor especificado pelo processo que deseja receber esta mensagem de notificação. |
| ham_action_waitfor() | Permite inserir atrasos entre ações consecutivas em uma sequência. |
| ham_action_heartbeat_healthy() | Redefine o mecanismo de pulsação para uma entidade que anteriormente havia perdido o envio de pulsações e acionou uma condição de pulsação perdida, mas agora se recuperou. |
| ham_action_log() | Reporta esta condição a um mecanismo de registo. |
Action Fail (Ações de falha de ação)
Para aumentar ainda mais a robustez do gerenciador de alta disponibilidade, é possível definir ainda uma ação alternativa, chamada action_fail, que é executada quando uma ação em uma lista de ações falha.
| Ação | Descrição |
| ham_action_fail_execute() | Executa um comando arbitrário (por exemplo, para iniciar um processo). |
| ham_action_fail_notify_pulse() | Notifica algum processo de que esta condição ocorreu. Esta notificação é enviada através de um pulso específico com valor especificado pelo processo que deseja receber esta mensagem de notificação. |
| ham_action_fail_notify_signal() | Notifica algum processo de que esta condição ocorreu. Esta notificação é enviada através de um sinal específico em tempo real com um valor especificado pelo processo que deseja receber esta mensagem de notificação. |
| ham_action_fail_waitfor() | Esta ação permite inserir atrasos entre ações consecutivas em uma sequência. |
| ham_action_fail_log() | Isso permite inserir uma mensagem de detalhamento personalizável no log de atividades mantido por um HAM. |
Multistaged recovery (Recuperação em vários estágios)
A recuperação de uma falha pode envolver mais do que reiniciar um único componente.
Imagine um cenário onde um processo está utilizando o NFS (Network File System) para acessar arquivos armazenados em um servidor de arquivos remoto. A perda de conectividade devido à uma falha no driver de rede vai resultar na desmontagem do NFS e perda do acesso aos arquivos.
Reiniciar apenas o driver de rede não vai resolver o problema causado pela sua falha. Isso pode restaurar a conectividade de rede, mas as montagens NFS perdidas não serão automaticamente recuperadas.
O gerenciamento de alta disponibilidade do QNX pode ser instruído para reiniciar o fs-nfs3 em caso de falha e também a remontar os diretórios apropriados conforme necessário após reiniciar o processo NFS. Este é o cenário típico de uma recuperação em vários estágios que o HAM do QNX está preparado para lidar.
HAM em ação
Para entender melhor como o HAM do QNX funciona na prática, preparei um exemplo que simula o monitoramento contínuo de um processo crítico e importante do nosso sistema.
Este programa fará o seguinte:
- Estabelecer uma conexão com o HAM
- Iniciar a entidade à ser monitorada
- Anexar a entidade
- Estabelecer uma condição e um evento
/* simple_restart.c */
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/netmgr.h>
#include <fcntl.h>
#include <ha/ham.h>
int main(int argc, char *argv[])
{
char *mqueuepath = "/sbin/mqueue"; // Caminho do processo a ser monitorado
int mqueuepid = -1; // PID inicial do processo (não especificado)
ham_entity_t *ehdl; // Manipulador da entidade monitorada pelo HAM
ham_condition_t *chdl; // Manipulador da condição de falha
ham_action_t *ahdl; // Manipulador da ação a ser executada em caso de falha
printf("High Availability Manager (HAM)\n");
// Conecta ao High Availability Manager
ham_connect(0);
// Anexa a entidade (processo mqueue) ao HAM para monitoramento
ehdl = ham_attach("mqueue", 0, mqueuepid, mqueuepath, 0);
if (ehdl != NULL)
{
// Define a condição de falha (quando o processo mqueue morre)
chdl = ham_condition(ehdl, CONDDEATH, "death", HREARMAFTERRESTART);
if (chdl != NULL)
{
// Define a ação de restart em caso de falha
ahdl = ham_action_restart(chdl, "restart", mqueuepath, HREARMAFTERRESTART);
if (ahdl == NULL)
{
printf("Falha ao adicionar ação\n");
}
else
{
printf("Monitorando o processo '%s'\n", mqueuepath);
}
}
else
{
printf("Falha ao adicionar condição\n");
}
}
else
{
printf("Falha ao adicionar entidade\n");
}
ham_disconnect(0);
exit(0);
}
Vamos usar o processo ‘mqueue’, (um gerenciador de fila de mensagens tradicional no QNX Neutrino) como exemplo. Ele será nossa entidade.
Em caso de falha neste processo, diversas ações podem ser tomadas, mas para simplificar, vamos considerar apenas reiniciá-lo.
Nossa condição será “death” (entidade morreu) e a ação será “restart”.
Você usa a função ham_attach() para anexar uma entidade que já está em execução ao HAM (bastaria utilizar seu PID) ou dizer à ele para iniciar um processo e depois adicioná-lo como uma entidade ao seu contexto.
Uma entidade pode ser qualquer processo no sistema
Depois que uma entidade for anexada, você poderá adicionar condições e ações a ela.
Entenda como isso funciona na documentação de ham_attach(), ham_condition() e ham_action_restart().
A imagem a seguir demonstra como este exemplo foi testado.
O utilitário de linha de comando “ham” inicia o Gerenciador de Alta Disponibilidade do QNX. Imediatamente o processo guardião (espelho do HAM) é iniciado também. São os processos com PID 2105386 e 2109487.
Nosso programa exemplo (simple_restart) é executado, o processo mqueue é disparado (PID 2162726) e ele passa a monitorar esta entidade.
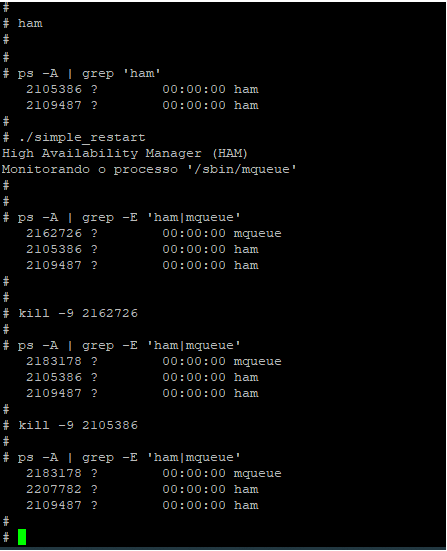
Para simular uma falha, utilizo o kill -9 2162726 que vai enviar um sinal para “matar” este processo.
Imediatamente teremos a ação do HAM reiniciando o processo e reestabelecendo o sistema. Perceba o novo PID 2183178 de mqueue.
Nada poderá interrompê-lo a não ser que o HAM seja explicitamente instruído à parar de monitorá-lo usando o utilitário de linha de comando hamctrl –stop ou a função ham_stop() da API.
Adicionalmente testei a resiliência do próprio HAM e a ação do seu Guardião enviando kill -9 2105386 para interrompê-lo.
Observe que o Guardião (agora o novo HAM) cria um novo Guardião para si antes de tomar o lugar do HAM original.
Como o par HAM/Guardião monitora um ao outro, a falha de qualquer um deles pode ser completamente recuperada. Novamente, a única maneira de parar o HAM é instruí-lo explicitamente para encerrar o Guardian e depois encerrar a si mesmo.
Conclusão
A implementação de sistemas de alta disponibilidade, especialmente em ambientes embarcados, requer uma abordagem ampla para lidar com falhas de hardware, software, fatores ambientais e humanos, além de ataques de segurança. O QNX, com sua arquitetura de microkernel, já fornece uma base robusta para alta disponibilidade ao isolar processos e proteger a memória.
O High Availability Manager (HAM) e o Guardian do QNX adicionam uma camada adicional de resiliência ao monitorar processos críticos e executar ações de recuperação de forma automatizada e inteligente. Essa abordagem permite que sistemas se recuperem de falhas sem a necessidade de intervenções manuais extensivas, minimizando o tempo de inatividade e aumentando a confiabilidade geral do sistema.
A capacidade do HAM de realizar recuperações em vários estágios e de lidar com dependências entre processos é particularmente valiosa em cenários onde a simples reinicialização de componentes individuais não seria suficiente.
Em resumo, no QNX RTOS, temos combinação de uma arquitetura microkernel robusta com mecanismos avançados de monitoramento e recuperação para aplicações que exigem alta disponibilidade e tolerância a falhas.
Referências
- QNX Software Systems. (n.d.). Inherent HA. https://www.qnx.com/developers/docs/8.0/com.qnx.doc.neutrino.sys_arch/topic/ham_Inherent_HA.html
- QNX Software Systems. (n.d.). High Availability Manager. https://www.qnx.com/developers/docs/8.0/com.qnx.doc.neutrino.sys_arch/topic/ham_HAM.html
- QNX Software Systems. (n.d.). The HAM and the Guardian. https://www.qnx.com/developers/docs/8.0/com.qnx.doc.neutrino.sys_arch/topic/ham_SELFMONITOR.html
- QNX Software Systems. (n.d.). HAM API. https://www.qnx.com/developers/docs/8.0/com.qnx.doc.neutrino.sys_arch/topic/ham_API.html
- QNX Software Systems. (n.d.). High Availability Framework Developer’s Guide. https://www.qnx.com/developers/docs/8.0/com.qnx.doc.ham/topic/about.html














