
Neste artigo daremos continuidade ao tema Regressão Linear. Se você chegou aqui sem antes ter lido a parte 1, sugiro que faça isso primeiro, ok! Vamos aprender sobre Correlação, covariância e Determinação.
Um Exemplo Abstrato
Vamos ver um exemplo abstrato com duas variáveis para entender um pouco mais na prática sobre regressão linear. Considere a seguinte tabela de valores
| Instância | Variável 1 | Variável 2 |
| x1 | 40 | 60.000 |
| x2 | 69 | 75.000 |
| x3 | 20 | 45.000 |
| x4 | 70 | 76.000 |
| x5 | 35 | 50.000 |
| MÉDIA | 46,8 | 61.000 |
| DESVIO PADRÃO | 21,99 | 14131,53 |
Vou adotar a letra V para denotar VARIÁVEL, e Va e Vb para denotar duas diferentes variáveis. Os iteradores são as letras i e j. Vamos primeiro calcular algo chamado de covariância, uma medida que verifica se existe alguma relação entre as variáveis. A equação 1 apresenta a fórmula:
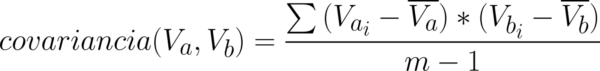
Agora vamos fazer o cálculo para cada uma das instâncias desse pequeníssimo dataset. Primeiro vamos subtrair o valor das instâncias da variável 1 da média.
| Instância | Variável 1 | Variável 2 | Vai – Vai_média |
| x1 | 40 | 60.000 | -6,8 |
| x2 | 69 | 75.000 | 22,2 |
| x3 | 20 | 45.000 | -26,8 |
| x4 | 70 | 76.000 | 23,2 |
| x5 | 35 | 50.000 | -11,8 |
| MÉDIA | 46,8 | 61.000 | |
| DESVIO PADRÃO | 21,99 | 14131,53 |
Agora a variável 2:
| Instância | Variável 1 | Variável 2 | Vai – Va_média | Vbi – Vb_média |
| x1 | 40 | 60.000 | -6,8 | 59.953,2 |
| x2 | 69 | 75.000 | 22,2 | 74.953,2 |
| x3 | 20 | 45.000 | -26,8 | 44.953,2 |
| x4 | 70 | 76.000 | 23,2 | 75.953,2 |
| x5 | 35 | 50.000 | -11,8 | 49.953,2 |
| MÉDIA | 46,8 | 61.000 | ||
| DESVIO PADRÃO | 21,99 | 14131,53 |
Ótimo! Agora temos de multiplicar esses valores
| Instância | Variável 1 | Variável 2 | Vai – Va_média | Vbi – Vb_média | Vai– Va_média*Vbi – Vb_média |
| x1 | 40 | 60.000 | -6,8 | 59.953,2 | -407.681,76 |
| x2 | 69 | 75.000 | 22,2 | 74.953,2 | 1.663.961,04 |
| x3 | 20 | 45.000 | -26,8 | 44.953,2 | 1.204.745,76 |
| x4 | 70 | 76.000 | 23,2 | 75.953,2 | 1.762.114,24 |
| x5 | 35 | 50.000 | -11,8 | 49.953,2 | -589.447,76 |
| MÉDIA | 46,8 | 61.000 | |||
| DESVIO PADRÃO | 21,99 | 14131,53 |
Legal, agora, vamos somar a última coluna:
| Instância | Variável 1 | Variável 2 | Vai – Va_média | Vbi – Vb_média | Vai– Va_média*Vbi – Vb_média |
| x1 | 40 | 60.000 | -6,8 | 59.953,2 | -407.681,76 |
| x2 | 69 | 75.000 | 22,2 | 74.953,2 | 1.663.961,04 |
| x3 | 20 | 45.000 | -26,8 | 44.953,2 | 1.204.745,76 |
| x4 | 70 | 76.000 | 23,2 | 75.953,2 | 1.762.114,24 |
| x5 | 35 | 50.000 | -11,8 | 49.953,2 | -589.447,76 |
| MÉDIA | 46,8 | 61.000 | |||
| DESVIO PADRÃO | 21,99 | 14131,53 | SOMA | 1.224.200,00 |
Agora que temos a soma, precisamos dividir pelo total de instâncias:
1.224.200,00 / 4 = 244.840,0
O que esse valor nos diz? Na covariância se o resultado for maior que zero então significa que existe uma dependência entre elas, neste caso, quanto maior a variável 1 maior também a variável 2. Se o valor resultante da covariância for menor que zero, também há dependência, daí indica que quanto menor a variável 1, menor a variável 2. Mas e se for igual a zero? Nesse caso, as variáveis são independentes. Em nosso exemplo a covariância é positiva, indicando que quanto maior a variável 1 maior também a variável 2.
Mas convenhamos que esse valor que encontramos é grande não é mesmo? O que deveríamos fazer então para que seja mais fácil de analisar esse exemplo abstrato? Se você pensou “normalização” ou “escala”, pensou certo! Neste caso, precisamos escalar os valores antes de realizar os cálculos.
Ok! Aprendemos como calcular a covariância, que nos diz algo sobre a relação entre os dados e isso é importante para depois decidirmos se vamos ou não usar regressão linear no nosso problema. Agora, vamos calcular outra medida que também ajuda com isto, a correlação, que é dada pela equação 2:
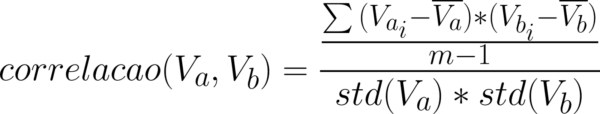
Como vocês podem notar, essa equação usa o resultado da covariância. O que precisamos fazer agora é multiplicar o desvio padrão de x com y:
21,99 * 14131,53 = 310.797,18
E dividir o resultado da covariância por este valor:
244.840,0 / 310.797,18 = 0,7878
Com isso chegamos no valor de correlação. Quando esse valor é muito próximo de 1, indica que uma variável pode ser explicada pela outra e, portanto, existe uma relação entre elas. Quando a variável tem um valor próximo de 0, indica que não existe nenhuma relação entre as variáveis. Mas e se tivermos um valor negativo ou muito próximo de -1? Neste caso, indica que uma variável aumenta e a outra diminui e, portanto, há alguma relação entre elas. Legal, essa medida aqui já nos diz uma coisa sobre os dados diferente da covariância.
Vamos ver então uma última medida que vai nos ajudar a entender ainda melhor os dados e tomar nossa decisão a respeito de qual modelo de aprendizado de máquina usar. A equação 3 mostra o coeficiente de determinação:

Então, o que precisamos fazer é elevar ao quadrado o resultado da correlação, portanto:
(0,7878)2 = 0,6206
Esse valor nos diz que 62% da variável 2 pode ser explicada pela variável 1, abstraindo podemos dizer que p% da variável dependente (alvo, target) pode ser explicada pelas variáveis explanatórias. Quanto mais próximo de 1, mais explicação as variáveis explanatórias (ou atributos de entrada) fornecem. Portanto, podemos resumir essas medidas na Tabela 2.
| COEFICIENTE | RESULTADOS | OBSERVAÇÕES |
| Covariância | cov > 0 : x e y são dependentes e qto maior é x maior é y cov == 0 : x e y são independentes cov < 0 : x e y são dependentes e qto menor é x menor é y | Existe alguma relação entre as variáveis? |
| Correlação | corr = ~ +1 : x e y são dependentes e a variação de x pode ser explicada pela variação de y corr == 0 : x e y são independentes corr = ~ -1 : x e y são dependentes e a qdo a variável x aumenta a variável y diminui | A variabilidade de uma variável Va pode ser explicada pela variação de outra variável Vb |
| Determinação | det = ~ 1 : mais Va explica Vbdet = ~ 0 : menos Va explica Vb | P% da variável Vb pode ser explicada pela variável Va |
| Correlação Muito Fraca: 0,0 à 0,19 | 0,0 à – 0,19 Correlação Fraca: 0,20 à 0,39 | -0,20 à -0,39 Correlação Moderada: 0,40 à 0,69 | -0,40 à -0,69 Correlação Forte: 0,70 à 0,89 | -0,70 à -0,89 Correlação Muito Forte: 0,90 à 1,00 | -0,90 à -1,00 | ||
Portanto, se ao analisar os dados você notar que as variáveis são independentes, então a regressão linear não é o modelo mais adequado para ser utilizado. Além disso, ainda que exista correlação entre as variações, pode não haver causa, por isto usar apenas a correlação não é suficiente para determinar o uso da regressão linear. Lembrem-se, para a regressão linear é necessário que haja uma RELAÇÃO LINEAR entre as variáveis, ou seja, as variáveis devem variar conjuntamente.
Calculando MSE
Agora que já aprendemos essa informação, vamos considerar que temos um conjunto de dados em que a regressão linear pode ser aplicada. Vamos usar o erro quadrático médio como função de custo. Para tanto, considere a Tabela 2.
| Instância | Variável 1 | Variável 2 |
| x1 | 300 | 320 |
| x2 | 430 | 425 |
| x3 | 112 | 122 |
| x4 | 27 | 58 |
| x5 | 280 | 198 |
| x6 | 10 | 100 |
Se plotarmos um gráfico simples com estes valores vamos obter a Figura 1.

Notem que no eixo X está a variável Va e no eixo Y a Vb. Visualmente, conseguimos perceber que o algoritmo terá alguma, mas não muita, dificuldade para encontrar a melhor reta que descreve esses dados. Se você pegar uma régua e colocar em cima da figura, vai notar que dá pra traçar uma reta que melhor se ajusta aos dados. A função de custo é dada pela Equação 4 a seguir:
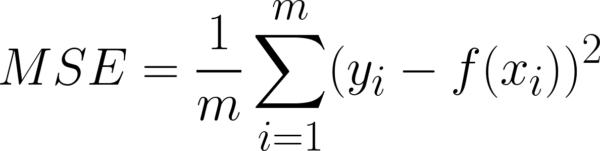
Que pode ser estendida para a Equação 5:
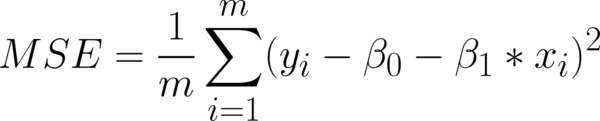
Lembram das betas? Falamos deles no artigo anterior. Caso não se lembre, volte lá e dê uma lida rápida! Então, vamos calcular o erro agora para entender melhor o que significa penalizar os maiores erros.
| Instância | Variável 1 | Variável 2 | Erro |
| x1 | 300 | 320 | (300-320)2 = 400 |
| x2 | 430 | 425 | (430-425)2 = 25 |
| x3 | 112 | 122 | (112-122)2 = 100 |
| x4 | 27 | 58 | (27-58)2 = 961 |
| x5 | 280 | 198 | (280-198)2 = 6724 |
| x6 | 10 | 100 | (10-100)2 = 8100 |
Bom, agora precisamos somar esses valores e depois dividir pelo total de instâncias.
MSE = 400 + 25 + 100 + 961 + 6724 + 8100 = 16310 / 6 = 8155
O menor erro está em x2 enquanto que o maior erro está em x6. Perceberam que quanto menor a diferença entre Va e Vb, menor é o erro? Mas quando a diferença entre eles é grande, o valor do erro é muito grande? É dessa forma que o algoritmo sabe o quão longe aquele dado está da reta e essa distância sendo muito longe, significa que o modelo ainda não está adequado aos dados. Como consequência, o valor do MSE será alto. É necessário então iterar por N vezes, isto é, repetir N vezes o processo, até que o valor do MSE seja minimizado para um valor aceitável, preferencialmente perto de zero. Neste ponto entra o gradiente descendente, mas vou falar sobre no próximo artigo!













