
Continuando nossa série de artigos sobre inteligência artificial com foco em Redes Neurais Artificiais, abordaremos agora as diferentes arquiteturas e topologias de Redes Neurais Artificiais existentes, assim como as suas formas de treinamento. Quando nos referimos à arquitetura de uma rede neural estamos nos referindo sobre a disposição dos neurônios, um em relação ao outro, seguindo as conexões sinápticas comentadas no artigo anterior. Já a topologia da rede se refere às diferentes composições estruturais possíveis com diferentes quantidades de neurônios nas camadas de entrada, intermediária e de saída da rede.
A camada de entrada é responsável pelo recebimento dos dados/sinais/amostras a serem analisados, assim como a correspondente associação com os pesos de entrada. A camada intermediária ou escondida tem por finalidade extrair as informações associadas ao sistema inferido, sendo também responsável pela maior parte do processamento destes dados. Já a camada de saída agrega os dados das camadas anteriores e ativa uma resposta adequada.
As arquiteturas mais usuais das RNA’s são:
FeedForward de Camada Simples: Uma camada de entrada diretamente associada a um ou mais neurônios que vão gerar a resposta de saída (figura 1). Observe que o fluxo de dados segue sempre em direção à camada de saída. São empregadas em problemas de classificação de padrões e filtragem. Tipos: Perceptron e Adaline.

Os Melhores Treinamentos sobre Sistemas embarcados e IoT
Cursos com professores qualificados para acelerar sua carreira e projetos

FeedForward de Camadas Múltiplas: Constituída por uma ou mais camadas escondidas de neurônios (figura 2). São empregadas em problemas de aproximação de funções, classificação de padrões, identificação de sistemas, otimização, robótica e controle de processos. Tipos: Perceptron Multicamadas, Redes de Base Radial.
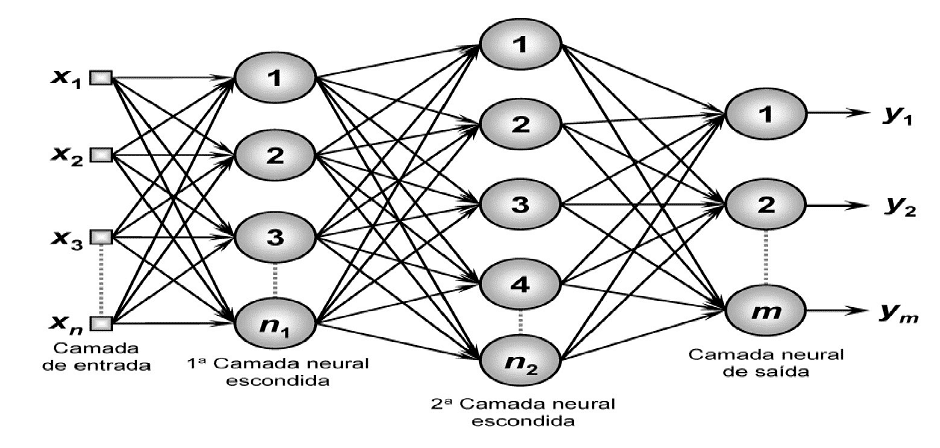
Recorrente ou Realimentada: Suas saídas são realimentadas como sinais de entrada para outros neurônios, sendo assim empregadas para o processamento de sistemas variantes no tempo (figura 3). São empregadas em previsões de séries temporais, otimização, identificação de sistemas e controle de processos. Tipos: Hopfield e Perceptron Multicamadas com Realimentação.

Estrutura Reticulada: Consideram a disposição espacial dos neurônios (figura 4) com o propósito da extração de características do sistema, ou seja, sua localização espacial serve para ajuste de seus pesos e limiares. São empregadas em problemas de agrupamento, reconhecimento de padrões, otimização de sistemas, etc. Tipo: Kohonen.

Treinamento da Redes Neurais Artificiais
Para que uma RNA atenda nossos objetivos ela deverá ser treinada. O termo treinamento de uma rede neural consiste basicamente em fazê-la adotar valores de pesos e limiares baseados em suas amostras de entrada, de modo que qualquer outra amostra futura apresentada a ela seja corretamente classificada. Isto é, apresentaremos nossas amostras/dados na entrada da rede e direcionaremos uma resposta desejada fazendo com que a rede seja obrigada a modificar seus pesos e limiares. Assim qualquer outro valor apresentado a ela depois que a rede estiver corretamente treinada produzirá uma saída ou resultado igual ou próximo do desejado.
Normalmente para treinarmos uma RNA e verificarmos se os pesos estão adequados teremos que dividir as amostras existentes entre treinamento e validação da rede. Sugere-se que a divisão seja 60% a 90% amostras para treinamento e 40% a 10% para testes. Denomina-se época de treinamento a cada vez que apresentarmos uma amostra para ajuste dos pesos sinápticos e limiares da rede. Quanto os tipos de treinamento estes podem ser:
Supervisionado: Deve-se dispor das amostras e das respectivas saídas desejadas para que os pesos e limiares sejam ajustados continuamente pelo algoritmo de aprendizagem.
Não Supervisionado: A saída deve se auto organizar em relação às particularidades do conjunto de amostras e assim identificar subconjuntos similares. Seus pesos e limiares são ajustados pelo algoritmo de aprendizagem de modo a refletir estas particularidades.
Com Reforço: Similar ao treinamento supervisionado, contudo seu algoritmo visa ajustar os pesos e limiares baseando-se em informações procedentes da interação com o sistema mapeado, visando reforçar as respostas satisfatórias.
Lote de Padrões (Off-Line): Apresenta-se primeiramente todo o conjunto de amostras para então se ajustar os pesos e limiares da rede.
Padrão por Padrão (On-Line): Os pesos e limiares são ajustados após a apresentação de cada amostra permitindo que a mesma seja descartada posteriormente. Este tipo de treinamento é empregado quando o sistema a ser mapeado sofre variações ao longo do tempo. Observe que devido às características do sistema variante, este tipo de treinamento somente fornecerá respostas precisas após a apresentação de um número significativo de amostras.
No próximo artigo iremos analisar e explorar as características de uma rede perceptron simples.
Referências
[1] Silva, Ivan N.; Spatti, Danilo H.; Flauzino, Rogério A; Redes Neurais Artificiais para engenharia e ciências aplicadas, Artliber, 2010.














Muito boa esse série de artigos! Parabéns!
Amei o artigo e olha que também sou articulista aqui no Embarcados. Estou estudando o assunto para o meu Doutorado e o seu artigo veio muito a calhar. Se cair na prova quais as diferenças entre os tipos de arquiteturas de RNAs eu já sei responder ahahhahahaha. Thanks.