
Introdução
Em processadores que não possuem hardware dedicado a realizar cálculos com ponto flutuante, as operações com este tipo de variável tornam-se muito caras em termos de tempo de processamento. Uma vez que alguns sistemas, como filtros digitais, exigem pequenos períodos de amostragem, isso é um problema.
Neste artigo será apresentada uma alternativa ao ponto flutuante, o ponto fixo. Nesta abordagem, os valores, ao serem salvos, são multiplicados por uma base, fazendo com que as casas decimais sejam, agora, vistas como números inteiros. A lógica das operações é então feita via software, levando em conta as particularidades dessa representação.
Ponto Fixo
O objetivo desta abordagem é fazer com que números decimais possam ser representados utilizando variáveis do tipo inteiro. Para processadores que não possuem circuitos dedicados a realizar operações com ponto flutuante, estas instruções são implementadas por software pelo compilador. Uma vez que as operações com números inteiros são feitas por hardware, há um ganho considerável de tempo.
No artigo “Entendendo a Aritmética em Ponto Fixo“, por Caio Moraes, as operações são explicadas com mais detalhes.

Os Melhores Treinamentos sobre Sistemas embarcados e IoT
Cursos com professores qualificados para acelerar sua carreira e projetos
Conversão
Basicamente, precisamos apenas multiplicar o valor desejado por uma base. O exemplo a seguir ilustra a conversão de um número decimal para sua representação em ponto fixo utilizando como base :
Sendo assim, um número que era antes real (10.25), pode ser armazenado em uma variável do tipo inteiro (2624) sem que o seu valor seja prejudicado.
Para desfazer a conversão a fim de encontrar o número real representado, basta dividir o valor pela base.
Operações
As operações de soma e subtração entre valores em ponto fixo não são diferentes daquelas normalmente realizadas. Em contrapartida, as operações de multiplicação e divisão precisam de uma correção, já que as bases dos números também serão multiplicadas ou divididas durante o processo.
A soma de dois números em ponto fixo resulta em um terceiro número, também em ponto fixo.
A subtração de dois números em ponto fixo também não necessita correção, já que resulta em um número também em ponto fixo.
Ao realizar a multiplicação, a base dos números é multiplicada ao quadrado, fazendo com que o resultado precise ser corrigido dividindo-o pela base.
Sem correção:
Com correção:
A multiplicação de um número representado em ponto fixo por um inteiro normal resulta em um número em ponto fixo sem que seja necessária correção.
Na operação de divisão, as bases são canceladas. É necessário, então, multiplicar o resultado pela base para que a representação esteja correta.
Sem correção:
Com correção:
Equação de diferenças
Partiremos do processamento da equação de diferenças implementado no artigo “Sistemas Dinâmicos e Equações de Diferenças com a FRDM KL25Z“. Serão realizadas a conversão dos coeficientes para sua representação em ponto fixo e, posteriormente, as correções das operações.
Implementação
O código a seguir implementa o sistema de segunda ordem apresentado no artigo mencionado anteriormente. Foram feitas as adaptações para que os coeficientes da equação possam ser representados em ponto fixo.
#include "Sistema.h"
#define N 19
#define BASE (1<<N)
uint16_t ts = 50; //50 ms
#define MAXCOEF 3
int16_t entrada[MAXCOEF], saida[MAXCOEF];
int16_t atual = 0;
#define MAX_X 3
int32_t coefx[MAX_X] = {0*BASE,0.0387857*BASE,0.0345066*BASE};
#define MAX_Y 3
int32_t coefy[MAX_Y] = {1*BASE,-1.6314*BASE,0.704688*BASE};
void initSist(){
uint8_t i;
for (i = 0; i < MAXCOEF; i++){
entrada[i] = 0;
saida[i] = 0;
}
atual = 0;
}
uint16_t getTs(){
return ts;
}
uint16_t equacaoDiff(uint16_t x){
uint8_t i;
int16_t anterior;
int64_t y = 0; //64 bits para evitar overflow na soma de 32 + 32 bits
entrada[atual] = x; //Entrada = uint 12 bits
for (i = 0; i < MAX_X; i++){
anterior = atual - i;
if (anterior < 0){
anterior+= MAXCOEF;
}
y += entrada[anterior]*coefx[i]; //y = inteiro*ponto fixo = ponto fixo
}
for (i = 1; i < MAX_Y; i++){
anterior = atual - i;
if (anterior < 0){
anterior+= MAXCOEF;
}
y -= saida[anterior]*coefy[i]; // inteiro*ponto fixo
}
y >>= 19; //Y em ponto fixo é convertido para inteiro
saida[atual] = y;
atual ++;
atual%=MAXCOEF;
return (int16_t)y;
}
Neste código a base para conversão dos coeficientes em ponto fixo é (1<<19), ou , ou seja, um deslocamento de 19 bits. Como o MCU trabalha com 32 bits, este foi o tamanho das variáveis dos coeficientes, pois é o que provém maior desempenho.
Utilizando esta base, o menor número possível de ser representado é . Sendo assim, esta é a precisão da representação utilizada.
Os coeficientes de entrada e saída da equação de diferenças foram, então, multiplicados pela base. A variável Y, que é responsável por guardar o valor das operações, foi declarada como inteiro de 64 bits, a fim de evitar overflow nas operações com os coeficientes, que têm 32 bits.
As operações de multiplicação não precisaram ser corrigidas, já que consistem na multiplicação de um número inteiro por um número em ponto fixo. Esta operação resulta em um número também em ponto fixo e é armazenada na variável Y. Isto vale tanto para o vetor de entrada (x) quanto para o vetor de saída (y).
Ao final, Y representa o sinal de saída do sistema dinâmico, o qual deve ser convertido para sua representação inteira para que possa ser enviada ao conversor digital-analógico. Isto é feito por meio da divisão deste valor pela base da representação. Como neste caso o divisor é uma potência de 2, a divisão por pode ser resumida em um deslocamento de 19 bits à direita.
Resposta
A imagem a seguir é a resposta ao degrau unitário deste sistema.
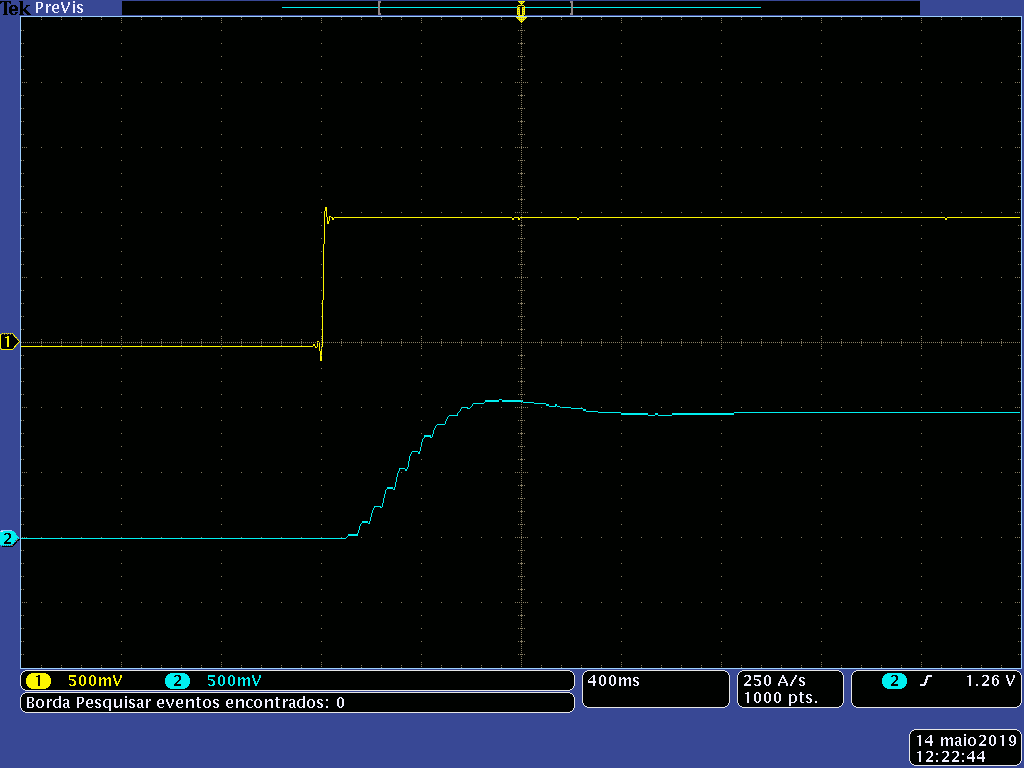
Em amarelo está a entrada do sistema e, em azul, a saída. Esta resposta é bastante semelhante àquela feita a partir do processamento da equação utilizando coeficientes em ponto flutuante, a qual foi apresentada nos artigos anteriores. Percebe-se, então, que seu comportamento continua satisfatório.
Desempenho
Medição
A fim de mensurar o ganho de tempo de processamento da equação de diferenças, será medido o tempo de processamento para uma variação no número de coeficientes de entrada e saída para cada uma das implementações, ponto flutuante e ponto fixo.
Para realizar esta medida, na tarefa responsável por ler o sinal, e fazer os cálculos, uma saída digital será acionada antes da equação ser processada, e desligada assim que retornar deste processamento.
O código a seguir mostra como isso foi feito no arquivo principal:
#include "FreeRTOS.h"
#include "Task.h"
#include "Sistema.h"
#include "adc.h"
#include "dac.h"
#include "gpio_x.h"
void sistema (void *p){
dacInit();
adcInit();
initSist();
PORTB_CLK();
PORTB_Mode(1, OUTPUT);
PORTB_Write(1, LOW);
TickType_t wakeTime = xTaskGetTickCount();
uint16_t entrada;
int16_t saida;
while (1){
vTaskDelayUntil(&wakeTime, getTs()*configTICK_RATE_HZ/1000);
entrada = adcRead(PT_B0);
PORTB_Write(1, HIGH);
saida = equacaoDiff(entrada >> 4);
PORTB_Write(1, LOW);
dacWrite(saida);
}
}
int main(void) {
xTaskCreate(sistema, "sistema_task", configMINIMAL_STACK_SIZE, NULL, tskIDLE_PRIORITY, NULL);
vTaskStartScheduler();
}
Desta maneira, a saída 1 de PORTB fica ativa somente durante o período gasto para processamento da equação. É possível, então, com auxílio de um osciloscópio realizar esta medida.
A imagem a seguir é um exemplo da forma de onda resultante quando observado o período em que este bit da PORTB tem nível alto.
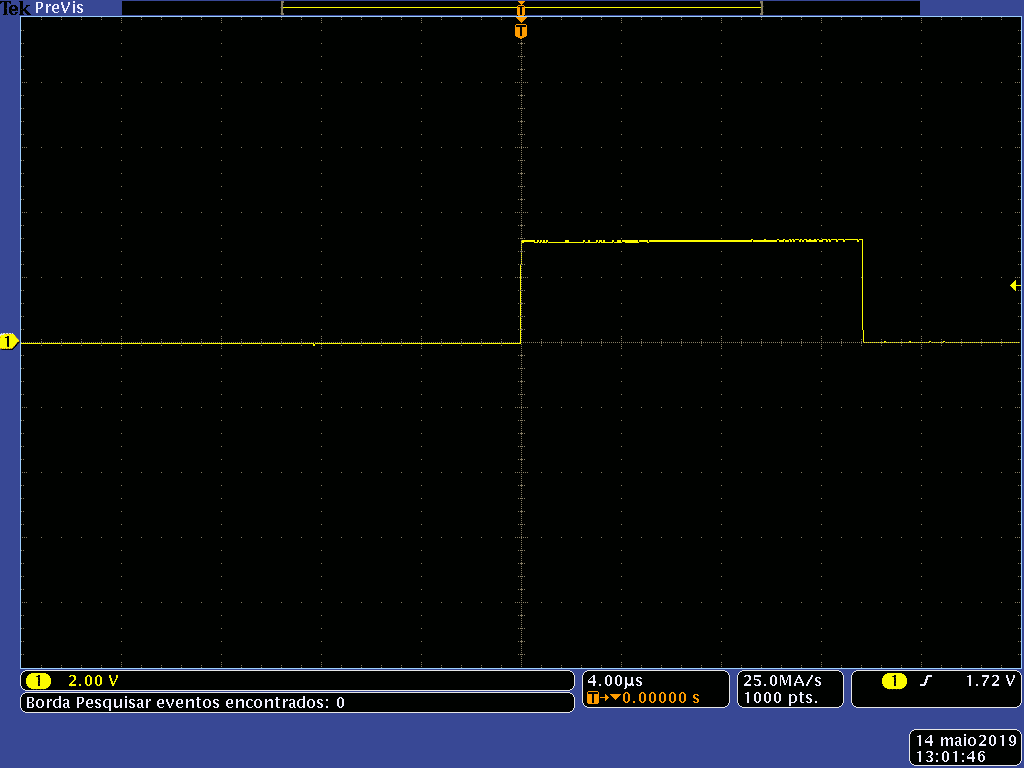
Neste exemplo, o bit 1 da PORTB fica ativo por aproximadamente 13.5.
Resultados
Para uma compilação sem otimização os seguintes dados foram obtidos:
Tabela 1: Desempenho com Ponto Flutuante
| Número de pares de coeficientes | Tempo de processamento ( |
| 1 | 40 |
| 2 | 70 |
| 3 | 105 |
| 4 | 150 |
| 5 | 180 |
Tabela 2: Desempenho com Ponto Fixo
| Número de pares de coeficientes | Tempo de processamento ( |
| 1 | 16 |
| 2 | 28 |
| 3 | 32 |
| 4 | 42 |
| 5 | 50 |
Aplicando a estes dados uma regressão linear obtém-se as seguintes equações:
É possível concluir que cada par de coeficientes gasta em média 36 microssegundos para operações em ponto flutuante. Já para ponto fixo, esse custo é de 8,6 microssegundos. Observa-se, então, uma melhoria de cerca de 4,2 vezes.
Existe, ainda, outra solução para melhora do desempenho, que é utilizar a otimização do compilador. Na IDE MCUXpresso esta opção está disponível nas configurações de projeto.
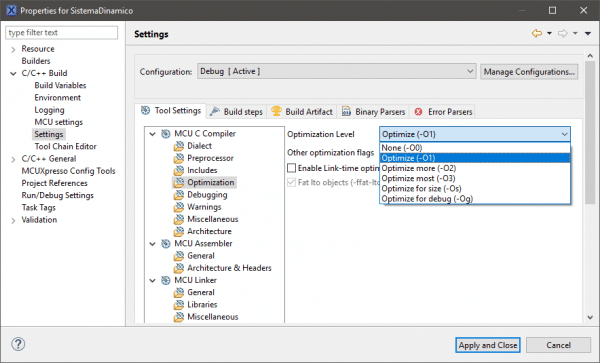
O tempo de processamento utilizando esta otimização está descrito nas tabelas a seguir:
Tabela 3: Desempenho com Ponto Flutuante otimizado
| Número de pares de coeficientes | Tempo de processamento ( |
| 1 | 18 |
| 2 | 52 |
| 3 | 90 |
| 4 | 125 |
| 5 | 150 |
Tabela 4: Desempenho com Ponto Fixo otimizado
| Número de pares de coeficientes | Tempo de processamento ( |
| 1 | 6,5 |
| 2 | 9 |
| 3 | 13 |
| 4 | 16 |
| 5 | 19 |
Por meio da regressão linear, cada par de coeficientes em ponto flutuante gasta 33,7 microssegundos. Para ponto fixo, 3,2 microssegundos. A melhora agora é mais significativa, de cerca de 10,5 vezes.
Conclusão
Neste artigo foi apresentada a abordagem do ponto fixo na implementação de sistemas dinâmicos digitais. Esta técnica tem por fim reduzir o tempo de processamento das operações para processadores que não possuem hardware dedicado para ponto flutuante em aplicações que requerem a representação de números decimais.
O funcionamento do sistema dinâmico não foi comprometido pela mudança na representação. O ganho de tempo de processamento foi significativo, sendo o ponto fixo até dez vezes mais rápido.
No próximo artigo serão demonstradas as aplicações deste sistema dinâmico como filtro digital, assim como abordar algumas técnicas de projeto para filtros.
Todos os códigos podem ser acessados em meu GitHub.
Saiba mais
Entendendo a Aritmética em Ponto Fixo
USB HID – Human Interface Device Class: Exemplo com a placa FRDM-KL25Z














Olá.
Acho que na explicação ali sobre a divisão, na parte conceitual do artigo, cabe observar o risco de underflow! No caso, o artigo fala em multiplicar o resultado da divisão pela base. Seria melhor multiplicar o dividendo pela base antes da divisão, tomando cuidado com o possível overflow deste.
Belíssimo artigo, muito direto e bem explicado.
Muito obrigado, Cassiano. Fico feliz em saber que gostou do texto.