
A cada dia os avanços tecnológicos colocam à disposição do projetista novos componentes e todo mundo faz de tudo para estar na crista da onda. Os componentes eletrônicos fazem muito mais e são mais rápidos e, as vezes, com mais eficiência; isto também tem sua parte negativa. Mais e melhores componentes também conseguem ser usados ineficientemente com mais facilidade. A arte de fazer com eficiência é cada vez mais rara nos projetos eletrônicos. Infelizmente, os atuais níveis de abstração usados em projeto com lógica programável mascaram geralmente isto. O projetista fica cada vez mais afastado da implementação física e tem a tendência de não se atentar para o que está fazendo, que é o de descrever o comportamento de um circuito eletrônico.
Com isto em mente iremos fazer um projeto simples em FPGA para implementar um dos blocos básicos em DSP, um filtro média-móvel. São filtros muito simples, mas não por isso pouco eficientes se usados e implementados da forma correta. Às vezes, os projetistas subestimam estes filtros pela sua simplicidade, mas para algumas aplicações estão próximos do ideal.
A ideia por trás do filtro é adicionar uma série de amostras no entorno da amostra que querermos filtrar para reduzir o ruído ou dispersão da amostra.
A função que descreveria o filtro seria:

Os Melhores Treinamentos sobre Sistemas embarcados e IoT
Cursos com professores qualificados para acelerar sua carreira e projetos
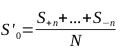
A tarefa será procurar uma solução em lógica programável que forneça um resultado matematicamente equivalente a este.
Implementando em hardware
Criar a implementação de um algoritmo em hardware significa implementar pensando nos recursos disponíveis neste hardware.
Para este caso, as amostras poderiam ser salvas em registros e as adições seriam implementadas nos geradores de funções da arquitetura de lógica programável selecionadas.
Vamos, por enquanto, não considerar a divisão e desenhar o dividendo da equação do filtro como um diagrama de blocos. O diagrama seria uma série de registros com as correspondentes adições. Olhando no desenho já evidenciamos um potencial problema: se a fórmula do filtro for implementada em hardware poderia criar muitos níveis de lógica.

Cada adição seria implementada num nível lógico. No exemplo iríamos ter 3 níveis de lógica, o que reduziria a frequência máxima de operação do filtro pelos tempos de propagação.
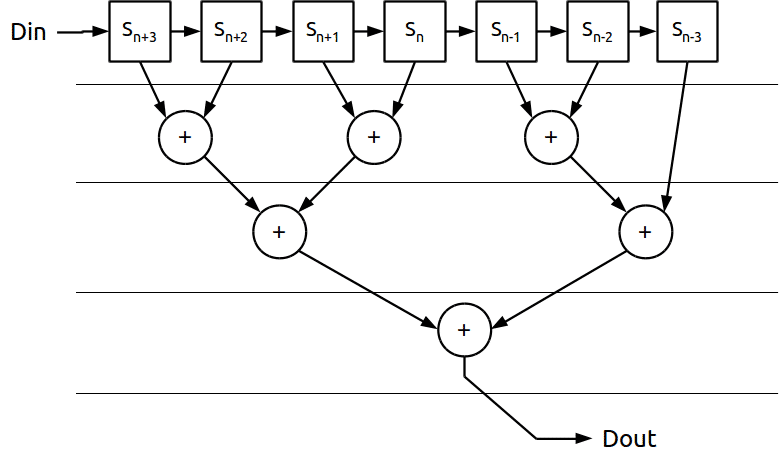
Podemos melhorar isso. Analisemos então as adições conforme chegam as amostras; um certo número de amostras permanecem constantes.
Poderíamos, portanto, salvar o valor já somado dessas amostras e usar mais de uma vez sem que seja necessário fazer todas as adições a cada nova amostra.
Resumindo, para cada nova amostra adicionaríamos uma amostra e subtrairíamos outra.

Reduziremos nosso diagrama para apenas duas operações; uma adição e uma subtração. Comparando as duas opções, esta versão tem um diferencial a mais, a máxima frequência de operação seria independente do número de passos do filtro. O diagrama adiciona também um acumulador para manter o valor dos resultados, “A”.
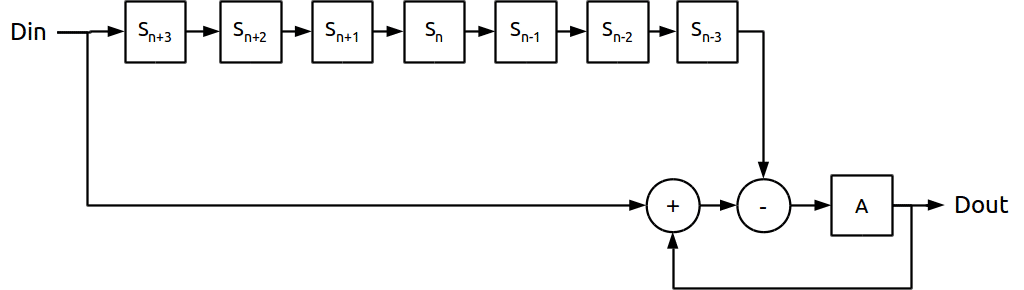
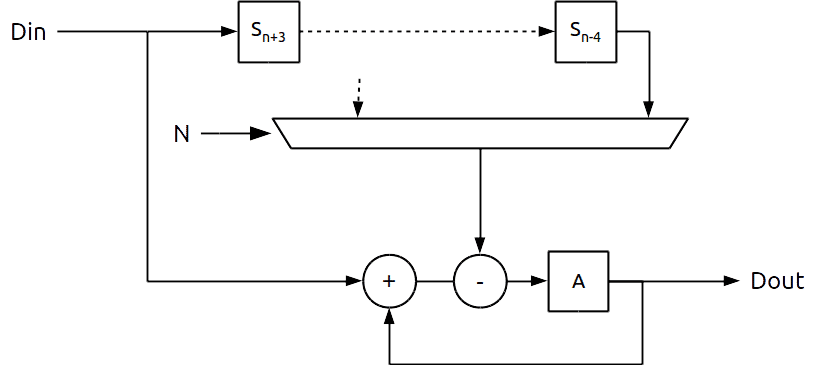
Esta arquitetura apresenta mais um benefício adicional. Montando um multiplexador nas saídas dos registros, implementaríamos um filtro Moving Average de comprimento variável dinamicamente.

Mais uma vez, redesenhamos o diagrama de blocos para simplificar. N seria um número relativo ao ajuste do número de passos.
Descrevendo hardware em VHDL
Vamos descrever em VHDL a arquitetura que terminarmos de criar, iniciaremos com a interconexão.
ENTITY MAF IS
PORT(
CLOCK : IN STD_LOGIC;
N : IN STD_LOGIC_VECTOR( 4 DOWNTO 0);
DI : IN STD_LOGIC_VECTOR(15 DOWNTO 0);
DO : OUT STD_LOGIC_VECTOR(15 DOWNTO 0)
);
END MAF;
A seguir descreveremos as estruturas de dados; definimos um tipo de dados ARRAY com comprimento 2N-1 e o número de bits igual ao range dos dados de entrada.
TYPE sDesc IS ARRAY (0 TO (2**N’length)-1) OF STD_LOGIC_VECTOR(DI’RANGE);
SIGNAL s : sDesc := (OTHERS => (OTHERS => ‘0’));
SIGNAL a : SIGNED(DI’length + N’length DOWNTO 0) := (OTHERS => ‘0’);
“s” seria o registro das amostras e “a” o acumulador conforme o desenho. Resta descrever a função de registro de deslocamento que seria conforme o código a seguir:
s <= DI & s(0 TO s’right-1);
e o acumulador com as adições e subtrações
a <= a + SIGNED(DI) – SIGNED(s(to_integer(UNSIGNED(N))));
Finalmente o processo que descreve o Filtro de Média-Móvel (“Moving Average Filter”) seria:
MovingAverageFilter : PROCESS(CLOCK)
BEGIN
IF rising_edge(CLOCK) THEN
s <= DI & s(0 TO s’right-1);
a <= a + SIGNED(DI) – SIGNED(s(to_integer(UNSIGNED(N))));
END IF;
END PROCESS MovingAverageFilter;
Verificação funcional do Hardware
Para verificar a funcionalidade criamos o banco de teste do filtro no simulador.
Os estímulos do banco de teste seriam clock, n e di; o sinal do seria o dado retornado pelo filtro. No dado de entrada adicionamos ruído nas amostras para conseguir uma SNR de 25dB, isto para que o sinal de entrada se aproximasse de uma amostragem real. Quantificamos em 16 bit, ponto fixo para uma dinâmica de -1,0 ; 1,0.
Dependendo da nossa ferramenta, a apresentação de resultados poderia ser evidente. Se ajustarmos as propriedades de apresentação, alinhados com o tipo de dado, as formas de onda de entrada, saída e acumulador seriam conforme a apresentados na figura a seguir:

Aplicando um zoom à imagem:
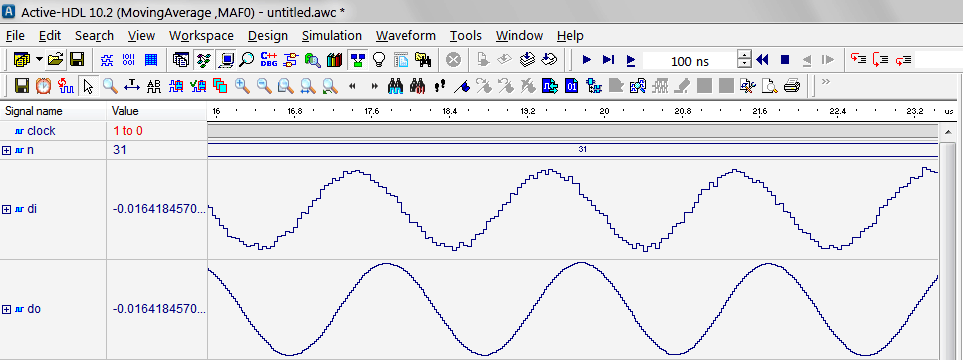
Conseguimos visualizar nas formas de ondas que o filtro estaria funcionando como esperado; os dados de entrada tem mais ruído que os dados de saída. O código completo do filtro ajustável está apreentado a seguir:
——————————————————————————-
—
— walter d. gallegos
— www.waltergallegos.com
— Programable Logic & Software
— Consultoria y Diseno
—
— Este archivo y documentacion son propiedad intelectual de Walter D. Gallegos
—
——————————————————————————-
LIBRARY IEEE;
USE IEEE.STD_LOGIC_1164.ALL, IEEE.NUMERIC_STD.ALL;
ENTITY MAF IS
PORT(
CLOCK : IN STD_LOGIC;
N : IN STD_LOGIC_VECTOR( 4 DOWNTO 0);
DI : IN STD_LOGIC_VECTOR(15 DOWNTO 0);
DO : OUT STD_LOGIC_VECTOR(15 DOWNTO 0));
END MAF;
ARCHITECTURE REV0 OF MAF IS
TYPE sDesc IS ARRAY (0 TO (2**N’length)-1) OF STD_LOGIC_VECTOR(DI’RANGE);
SIGNAL s : sDesc;
SIGNAL a : SIGNED(DI’length + N’length -1 DOWNTO 0);
SIGNAL d : SIGNED(DO’RANGE);
BEGIN
MovingAverageFilter : PROCESS(CLOCK)
BEGIN
IF rising_edge(CLOCK) THEN
s <= DI & s(0 TO s’right-1);
a <= a + SIGNED(DI) – SIGNED(s(to_integer(UNSIGNED(N))));
END IF;
END PROCESS MovingAverageFilter;
IntDiv : d <= a(a’left DOWNTO a’left-DO’left) WHEN N = “11111” ELSE
a(a’left-1 DOWNTO a’left-DO’left-1) WHEN N = “01111” ELSE
a(a’left-2 DOWNTO a’left-DO’left-2) WHEN N = “00111” ELSE
a(a’left-3 DOWNTO a’left-DO’left-3) WHEN N = “00011” ELSE
a(a’left-4 DOWNTO a’left-DO’left-4);
DO <= STD_LOGIC_VECTOR(d);
END REV0;
O multiplexador IntDiv implementa a divisão deslocando de um bit baseado no valor do N.
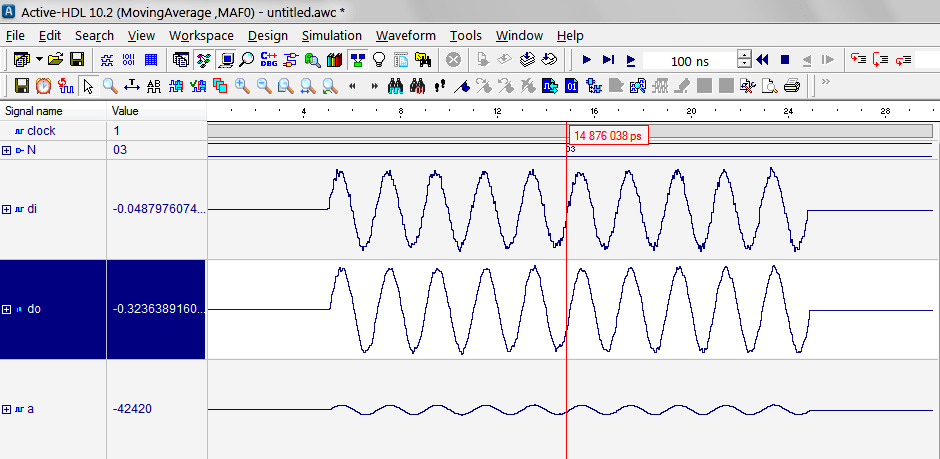
As formas de onda a seguir apresentam a entrada e saída do filtro mudando o número de passos, mostrando uma verificação rápida do funcionamento do mux. Veja que o range de saída permanece dentro da mesma faixa e, como esperado, o ruído na saída aumentou ao diminuir o número de passos.
A Implementação física
Na parte funcional, verificamos então que nosso filtro estaria dando os resultados esperados. Vamos passar para a implementação física. Até este momento o projeto foi genérico quanto aos componentes e s ferramentas; poderia ser implementado utilizando quaisquer componente de lógica programável.
De fato, uma vez ajustado o fluxo de implementação do fornecedor de FPGA à ferramenta, e isto fica fora do escopo deste post, usar um ou outro fornecedor traz pouca diferença no processo. No entanto, não é isso que observamos nos resultados; que seria fruto dos recursos disponíveis no componente e do uso que fizermos deles no código HDL.
Vamos, portanto, apenas conferir se os resultados da implementação coincidem com o esperado na descrição feita em VHDL para duas arquiteturas diferentes.
Deveríamos esperar 21 flip-flops para o acumulador mais 512 flip-flops para salvar as amostras, isto pelo código VHDL.

A implementação para a Arquitetura 1 resulta em 533 registros. Está excelente, é exatamente este o esperado. Mas alterando o componente, a implementação para uma outra arquitetura de FPGA mostra 21 registros, ou seja, o mesmo código utilizando uma arquitetura diferente dá um resultado extraordinariamente diferente.
Procurando a fonte de tal diferença vamos analisar a informação dos reports da ferramenta para a segunda arquitetura, além dos 21 registros temos 78 LUT que por sua vez são usadas de duas formas diferentes, 62 delas são usadas nos geradores de funções e as 16 restantes como memória.
Os registros para as amostras não seriam implementados em Flip-Flops, mas em LUTs usando um recurso de uma arquitetura particular. Aliás, o multiplexador realmente não consume recursos adicionais, faz parte da mesma LUT usada para salvar as amostras.

Mas isto não é fruto da magia negra; é fruto da técnica utilizada no projeto, o código VHDL foi escrito conhecendo a particularidade desta arquitetura de lógica programável em particular.
Portanto, um código VHDL genérico poderia ser implementado para quaisquer arquiteturas de lógica programável; mas se descrevermos nossa funcionalidade cuidadosamente poderíamos fazer uma descrição que, caso a arquitetura suportar, a ferramenta de implementação conseguiria otimizar usando os recursos disponíveis na arquitetura.
Fica uma pergunta no ar: Qual seria o resultado se não tivéssemos pensado um pouco no que poderia ser otimizado para a arquitetura selecionada antes de descrever em VHDL?
Partindo mais uma vez da função original
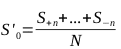
a descrição das adições poderia ser feita com o processo :
Adicao : PROCESS(s)
VARIABLE temp : SIGNED(a’RANGE);
BEGIN temp := (OTHERS =>’0′);
SumaS : FOR i IN s’RANGE LOOP
temp := temp + SIGNED(s(i));
END LOOP;
a <= temp;
END PROCESS Suma;
Os registros para salvar as amostras seriam outro processo
Registros : PROCESS(CLOCK)
BEGIN
IF rising_edge(CLOCK) THEN
s <= DI & s(0 TO s’right-1);
END IF;
END PROCESS Registros;
Bom, o código necessitaria de 512 Flip Flops e 564 LUTs para a mesma arquitetura que antes necessitou apenas 21 Flip-Flops e 78 LUTs, além do filtro não ser ajustável dinamicamente.
Fica então a cargo do leitor investigar porque, usando esta versão da descrição, a ferramenta não conseguiu otimizar a implementação dos registros mesmo dispondo dos recursos necessários.
A lição que aprendemos nessa implementação é que, se por um lado algum grau de abstração é produtivo, não deveríamos descrever hardware sem considerar como a descrição seria implementada numa arquitetura em particular.
Comentários finais
A intenção deste post foi apresentar uma metodologia de trabalho destacando a eficiência no uso dos recursos do que numa solução para um problema, a função para implementar foi simples para não complicar desnecessariamente o código e afastamos da linha de raciocino principal. Mas não por isso as conclusões seriam menos válidas.
Implementar funções DSP em hardware exige do projetista não apenas o conhecimento detalhado da função para implementar mas também o conhecimento da arquitetura de lógica programável sobre a qual seria implementada.
Migrar funções pensadas para outras soluções de implementação tem o risco potencial de criar soluções pouco otimizadas e um consumo de recursos desnecessário. Um ponto que não deveria esquecer quem tenta passar algoritmos de software para hardware.
Uma visão do projeto completo é imprescindível mas não reparar nos detalhes poderia rapidamente acrescentar muitas vezes os recursos consumidos. Se for implementar 32 destes filtros poderíamos gastar desde 21 X 32 = 672 até 533 X 32 = 17056 Flip-Flops dependendo do código e da arquitetura de lógica programável selecionada.
Esse texto foi originalmente publicado no link e foi revisado por Thiago Lima, que teve autorização do autor para publicação.
















Muito legal o tutorial.
O programa que você utilizou para simular é free?
Sabe se o modelsim tambem gera gráficos?
Abraços,
Oi William, desculpa o demorado do retorno.
A que usei foi a versão paga do Active-HDL, a WDG é o distribuidor da ferramenta para a região, mas você pode pegar a versão estudante que é free
https://www.aldec.com/en/products/fpga_simulation/active_hdl_student.
Abraços,