
Introdução
No post anterior foi abordado de maneira superficial o funcionamento básico do git. Vamos dar continuidade e detalhar um pouco mais como se cria e se usa um repositório git local e em seguida cobriremos o uso em um repositório remoto hospedando o código no Github.
Comandos Git
Primeiro vamos listar e explicar alguns comandos Git básicos que serão usados adiante:
git init
Inicializar um repositório git. Ao executar esse comando, git cria um subdiretório .git que contém os arquivos necessários do novo repositório.

Os Melhores Treinamentos sobre Sistemas embarcados e IoT
Cursos com professores qualificados para acelerar sua carreira e projetos
git add
Este comando possui diversas funções, como adicionar um arquivo em uma lista de arquivos a ser monitorado. Também funciona para salvar o estado de um arquivo que está sendo monitorado.
git rm
Remove um arquivo da lista de arquivos monitorados.
git commit
Cria um ponto de referência com o estado atual de todos os arquivos.
git status
Exibe o status dos arquivos no repositório (não monitorados, modificados e não salvos, salvos e prontos para commit, etc).
git branch
Cria ou muda de ramo de desenvolvimento. Também serve para listar todos os ramos existentes.
git checkout
Muda de ramo ou ainda serve para ignorar modificações locais, entre outras funcionalidades.
git push
Envia as modificações para o repositório remoto.
git pull
Busca modificações do repositório remoto.
git clone
Copia um repositório remoto na máquina local.
Repositório local
Para iniciar um repositório local, como explicado anteriormente basta executar o comando git init:
$ git init Initialized empty Git repository in /home/user/artigo/.git/
Note que o repositório .git foi criado como esperado. Crie um arquivo vazio com o nome teste.txt e execute o comando git status.
$ git status
On branch master
Initial commit
Untracked files:
(use "git add <file>..." to include in what will be committed)
teste.txt
nothing added to commit but untracked files present (use "git add" to track)
O git nos informa que existe um arquivo não monitorado (untracked) chamado teste.txt. Para que o git comece a monitorá-lo, execute git add:
$ git add ./teste.txt
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: teste.txt
Neste ponto, o arquivo teste.txt está sendo controlado pelo git. Modifique agora o arquivo e execute o comando git status novamente:
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: teste.txt
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: teste.txt
Notem que temos agora new file: teste.txt e também modified: teste.txt. Isso significa que o git detectou que houve uma modificação no arquivo teste.txt. Para adicionar essas modificações, basta executar novamente git add. Caso queira ignorar e retornar ao arquivo original (vazio), execute git checkout.
Crie e adicione um segundo arquivo teste2.txt.
$ git add ./teste2.txt
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: teste.txt
new file: teste2.txt
Agora o git monitora tanto teste.txt como teste2.txt. Caso queiram que o git pare de monitorar o arquivo, execute o comando git rm. Notem que o git dá dicas durante os comandos executados.
$ git rm --cached ./teste2.txt
rm 'teste2.txt'
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: teste.txt
Untracked files:
(use "git add <file>..." to include in what will be committed)
teste2.txt
Com o parâmetro –cached, o git somente para de monitorar o arquivo. Porém caso queira deletá-lo, execute o comando git rm sem o parâmetro –cached.
$ git add ./teste2.txt
$ git rm -f ./teste2.txt
rm 'teste2.txt'
$ git status
On branch master
Initial commit
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: teste.txt
Digamos que os arquivos do projeto estão num momento onde seria importante salvá-los como estão. Para isso, executamos o commando git commit para criar um ponto de referência a fim de sermos capazes de consultar mais tarde todos os arquivos desejados.
$ git commit -m "Commit de teste"
Commit de teste 1 file changed, 1 insertion(+) create mode 100644 teste.txt $ git log commit eb554073c0af31063589ae4243b9d9ed3e42db02 Author: Marcelo Jo <marcelojo@gmail.com> Date: Tue Feb 17 22:42:25 2015 -0500 Commit de teste user@Linux-Mint:~/Marme/projetos/artigo >
No comando de commit, executamos com o parâmetro -m para deixarmos uma mensagem para podermos identificar facilmente em que ponto estávamos. Com o comando git log, listamos todos os commits feitos.
Nos exemplos até agora, fizemos todas as alterações no ramo principal, chamado master. Às vezes temos a necessidade de criar ramificações para organizar melhor o projeto. Um exemplo seria criar um ramo para desenvolver algum código que você não tem certeza se vai funcionar ou não. Para isto, usamos o comando git branch.
$ git branch novo_branch $ git branch * master novo_branch $ git checkout novo_branch Switched to branch 'novo_branch'
No exemplo acima criamos o ramo novo_branch e para mudarmos para o novo ramo usamos git checkout. Também é possível fazer isso num comando só: git checkout -b novo_ramo.
No novo ramo, pode-se executar todos os comandos já conhecidos, adicionar arquivos, alterá-los, criar commits, etc. Digamos que as alterações nesse ramo não são importantes e não há a necessidade de salvá-los. Neste caso, basta excluir o ramo com o mesmo comando git branch com o parâmetro -d.
$ git branch -d novo_branch Deleted branch novo_branch (was eb55407).
No caso de querer salvar essas alterações e ainda adicionar no ramo principal master, usamos o comando git merge. Para simplificar o post, foi criado um arquivo teste2.txt e foi feito um commit no ramo novo_branch, mas os comandos serão omitidos.
$ git checkout master
$ git merge novo_branch
Updating eb55407..4a5ca52
Fast-forward
teste2.txt | 1 +
1 file changed, 1 insertion(+)
create mode 100644 teste2.txt
$ git log
commit 4a5ca520806dd461d820e691504492ab9a7a44db
Author: Marcelo Jo <marcelojo@gmail.com>
Date: Tue Feb 17 22:57:34 2015 -0500
Commit feito no novo_branch
commit eb554073c0af31063589ae4243b9d9ed3e42db02
Author: Marcelo Jo <marcelojo@gmail.com>
Date: Tue Feb 17 22:42:25 2015 -0500
Commit de teste
Primeiro, é necessário voltar ao ramo master e depois executar o comando merge. O Git explica que unificou os dois ramos adicionando no ramo master o arquivo teste2.txt. Executando git log a partir do ramo master, podemos notar que agora existem dois commits, um feito diretamente no ramo master e um segundo que foi feito no ramo novo_branch. Depois do merge, podemos deletar sem problemas o ramo novo_branch que todas as alterações já estão contidas no ramo master.
Repositório remoto
Podemos usar um repositório remoto para salvar nossos arquivos de modo a consultá-los ou mesmo editá-los de um outro computador diferente do computador local. Existem alguns provedores de repositórios Git e dentre os mais conhecidos estão Github e Bitbucket.
Como exemplo usaremos o Github. Após o login, no canto superior direito, no ícone +, selecione New repository.

Crie um nome para o seu repositório.
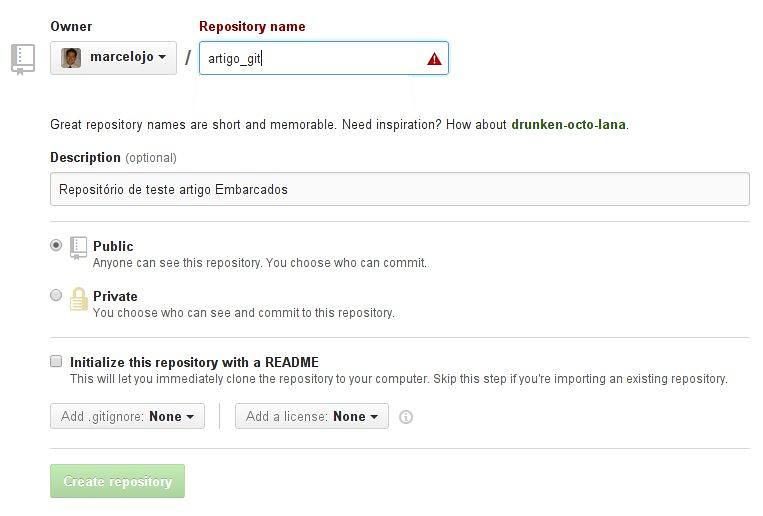
Pronto, seu repositório remoto está criado. Basta agora enviarmos nosso código local para lá.
git remote add origin https://github.com/marcelojo/artigo_git.git git push -u origin master Username for 'https://github.com': marcelojo@gmail.com Password for 'https://marcelojo@gmail.com@github.com': Counting objects: 6, done. Delta compression using up to 8 threads. Compressing objects: 100% (3/3), done. Writing objects: 100% (6/6), 489 bytes | 0 bytes/s, done. Total 6 (delta 0), reused 0 (delta 0) To https://github.com/marcelojo/artigo_git.git * [new branch] master -> master Branch master set up to track remote branch master from origin.
Primeiro precisamos dizer ao Git onde está o nosso repositório remoto. Isso é feito pelo comando git remote add origin. Depois usamos o comando git push para enviarmos o nosso ramo master para origin que está hospedado no Github. Vale lembrar que o comando git push pode ser usado a qualquer momento durante o desenvolvimento local a fim de sincronizar os arquivos locais e remotos.
Digamos que estamos em outro computador e gostaríamos de buscar os mesmos arquivos no Github. Isso é feito simplesmente pelo comando git clone:
$ cd ../ $ mkdir teste_artigo $ cd teste_artigo $ git clone https://github.com/marcelojo/artigo_git.git Cloning into 'artigo_git'... remote: Counting objects: 6, done. remote: Compressing objects: 100% (3/3), done. remote: Total 6 (delta 0), reused 6 (delta 0), pack-reused 0 Unpacking objects: 100% (6/6), done. Checking connectivity... done.
Conclusões
O Git é uma ferramenta muito flexível e poderosa porém o custo disso é a sua complexidade. Muitos dos comandos citados aqui recebem diversos parâmetros e podem ser usados de diversas formas. Este tutorial mostrou apenas o básico para que o leitor seja capaz, a partir do zero, de criar um repositório local e remoto. O Git disponibiliza um livro gratuito traduzido em Português do Brasil o qual explica de forma fácil e didática como usar essa fantástica ferramenta.















Gostaria de dar os parabéns para o post e aproveitando queria deixar o link para baixar o e-book gratuito para o pessoal que está aprendendo Spring Boot e possui uma parte de GitHub.
Segue o link para baixar → https://goo.gl/ZR9jX5
Artigo muito bom.