
Treinamento Modelo
Em sistemas embarcados, o processo de machine learning envolve o treinamento de um modelo com dados em uma plataforma externa, antes de implantá-lo na placa para realizar a inferência. Para o treinamento deste projeto, utilizaremos o Google Colab, uma plataforma online gratuita do Google que permite executar códigos Python diretamente no navegador.
Abra o arquivo de treinamento acessando o link https://colab.research.google.com/drive/11Lquu1coeWABdEYawaOWI_9TYlaYlP_M?usp=sharing e faça uma cópia. Esse exemplo mostra como treinar um modelo de menos de 20 kB que pode reconhecer 2 palavras-chave, “yes” e “no”, a partir de dados de fala. Se a entrada não pertencer a nenhuma das categorias, ela será classificada como “desconhecida” e, se a entrada for silenciosa, será classificada como “silêncio”.
O modelo usa como dataset Speech Commands Dataset que consiste em mais de 105.000 arquivos de áudio no formato WAVE de pessoas dizendo trinta palavras diferentes. Esses dados foram coletados pelo Google e liberados sob uma licença CC B. No dataset está disponível as seguintes palavras: “one”, “two”, “three”, “four”, “five”, “six”, “seven”, “eight”, “nine”, “yes”, “no”, “up”, “down”, “left”, “right”, “on”, “off”, “stop”, “go”, “backward”, “forward”, “follow”, “learn”, “unkown” label are: “bed”, “bird”, “cat”, “dog”, “happy”, “house”, “marvin”, “sheila”, “tree”, “wow”.
Você pode re-treinar o modelo para reconhecer qualquer combinação de palavras (2 ou mais) desta lista. Vamos modificar para as combinações “on” e “off”. Para isso, na primeira célula do arquivo no colab modifique a linha WANTED_WORDS = “yes,no” para “on,off”. Depois, execute a célula.

Os Melhores Treinamentos sobre Sistemas embarcados e IoT
Cursos com professores qualificados para acelerar sua carreira e projetos

Siga executando as demais células. A parte de treinamento do modelo pode demorar cerca de 2h.

Nessa etapa, o primeiro passo está sendo usar o comando !python tensorflow/tensorflow/examples/speech_commands/train.py que executa o script de treinamento de um modelo de reconhecimento de palavras-chave em áudio usando o TensorFlow.
Depois, são configurados alguns parâmetros importantes para o treinamento do modelo de reconhecimento de comandos de voz. Primeiro, é especificado o diretório onde os dados de áudio (dataset) estarão localizados. Também são definidas as palavras que o modelo deve aprender a reconhecer, além da porcentagem de áudio que será classificada como “silêncio” e “desconhecido”. Em seguida, é determinado o tipo de pré-processamento a ser aplicado aos dados de áudio e o valor do deslocamento da janela de análise do áudio, que define a quantidade de sobreposição entre as janelas de análise durante a extração das características do áudio.
A arquitetura do modelo de aprendizado de máquina é definida, além do número total de iterações do treinamento e a taxa de aprendizado (learning rate). Também é especificado o diretório onde os resultados do treinamento serão armazenados, incluindo o modelo final e os checkpoints. Os logs de treinamento, como gráficos e métricas, serão salvos em um diretório específico.
Após esse processo é preciso salvar em um modelo TensorFlow.

E depois, esse modelo é convertido em um TensorFlow Lite (TFLite) utilizando TFLiteConverter.from_saved_model(SAVED_MODEL) que carrega o modelo salvo e depois o método .convert() transforma em um arquivo .tflite. Além de converter também é necessário realizar a quantização que diminui ainda mais o tamanho do modelo. O código define o tipo de entrada e saída do modelo como tf.int8, o que indica que o modelo será quantizado para usar números inteiros de 8 bits.
A célula responsável por esse processo é:

Por fim é realizado a validação do modelo e é gerado um TensorFlow Lite para Microcontroladores com os comandos:
# Instale xxd
!apt-get update && apt-get -qq install xxd
# Converte para um arquivo C
!xxd -i models/model.tflite > model_data.cc
# Imprima o arquivo de código-fonte
!cat model_data.ccAdaptando o código ESP IDF
- Abra o projeto criado no artigo “Parte 1: Implementação de Reconhecimento de Comando de Voz com ESP-EYE e Machine Learning”.
- Em model.cc copiei seu novo modelo treinado.
- Em micro_model_settings.h substituta “yes” e “no” por “on” e “off”.

- Se você gravar o código na placa desta forma possivelmente alguns erros de Alocação do Tensor ocorrerão, como:
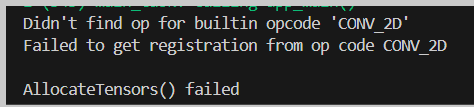
Isso ocorre porque as operações feitas no código não estão de acordo com as realizadas no modelo. O nosso modelo está realizando as seguintes operações:

Percebemos ali que o modelo usa DepthwiseConv2D, no entanto, às vezes, quando o modelo é convertido para .tflite, operações Conv2D e DepthwiseConv2D podem ser substituídas ou mescladas dependendo de como o TensorFlow Lite Micro faz a otimização. Portanto, adicionar ambas as operações (Conv2D e DepthwiseConv2D) ao MicroMutableOpResolver pode garantir compatibilidade. Dessa forma, acesse o arquivo main_functions.cc, busque a etapa que o código adiciona as operações e modifique para o seguinte:
static tflite::MicroMutableOpResolver<6> micro_op_resolver;
if (micro_op_resolver.AddReshape() != kTfLiteOk) {
return;
}
if (micro_op_resolver.AddConv2D() != kTfLiteOk) { // Adiciona CONV_2D
return;
}
if (micro_op_resolver.AddDepthwiseConv2D() != kTfLiteOk) {
return;
}
if (micro_op_resolver.AddRelu() != kTfLiteOk) {
return;
}
if (micro_op_resolver.AddFullyConnected() != kTfLiteOk) {
return;
}
if (micro_op_resolver.AddSoftmax() != kTfLiteOk) {
return;
}
5. Seria interessante que ao identificar algum comando pudéssemos controlar dispositivos, por exemplo, posso ligar luzes. Isso é possível fazer pelo arquivo command_responder.cc. Nele crie a seguinte função:
void RespondToCommand(const char* found_command,
float score, bool is_new_command) {
if (found_command[0] == 'o' && found_command[1] == 'n'){
printf("LIGAR\n");
}
if (found_command[0] == 'o' && found_command[1] == 'f'){
printf("DESLIGAR\n");
}
}

Você pode modificar a ação dessa função de acordo com sua necessidade, a título de exemplo estaremos imprimindo apenas na serial.
6. Em command_responder.h crie o protótipo da função RespondToCommand:
void RespondToCommand(const char* found_command, float score, bool is_new_command);

7. Acesse novamente o arquivo main_functions.cc, localize a linha 161 dentro do void loop. Nessa parte do código, há uma decisão sobre o uso do método argmax em vez do recognizer.

Substitua essa etapa pelo seguinte código:
// Setting a minimum threshold to consider a command as detected
const float kThreshold = 0.8f;
float output_scale = output->params.scale;
int output_zero_point = output->params.zero_point;
int max_idx = 0;
float max_result = 0.0;
// Dequantize output values and find the index of the maximum value
for (int i = 0; i < kCategoryCount; i++) {
float current_result =
(tflite::GetTensorData<int8_t>(output)[i] - output_zero_point) *
output_scale;
if (current_result > max_result) {
max_result = current_result;
max_idx = i;
}
}
// Display the result from argmax if it exceeds the threshold
if (max_result > kThreshold) {
MicroPrintf("Argmax Detected: %7s, score: %.2f", kCategoryLabels[max_idx],
static_cast<double>(max_result));
// Set found_command to the category label of the detected command
const char* found_command = kCategoryLabels[max_idx];
bool is_new_command = true; // Since we detected a command based on the threshold
// Call RespondToCommand with the detected command
RespondToCommand(found_command, max_result, is_new_command);
}

Funcionamento
Após realizar as modificações, grave o código na placa e abra o monitor serial. Será exibida a palavra com o maior score identificado. Caso seja uma palavra desconhecida, aparecerá “unknown”. Quando o microfone detectar a palavra “on”, além de exibir o score, a função de resposta será chamada e a mensagem “LIGAR” será mostrada. Da mesma forma, ao identificar a palavra “off”, será exibida a mensagem “DESLIGAR”.

Desafio
Use sua própria base de dados ou um outro dataset disponível na internet. A célula que deve ser modificada no arquivo do colab é a seguinte:

Em DATA_URL você pode colocar a fonte da sua nova base de dados. Um ótimo site para encontrar base de dados é https://www.kaggle.com/datasets.
E, caso você grave seus próprios áudios a estrutura de armazenamento deve ser em pastas nomeadas com o que está sendo falado no áudio, por exemplo:

Conclusão
Neste artigo, customizamos o exemplo “micro speech” disponibilizado no tflitemicro para ESP32. Passamos pelo processo de treinamento de um modelo de aprendizado de máquina usando o Google Colab e o TensorFlow, até a conversão do modelo para o formato TensorFlow Lite, adequado para dispositivos embarcados. A integração do modelo com o ESP-EYE permitiu a detecção das palavras-chave “on” e “off”, além de adicionar uma função com a capacidade de controlar dispositivos, como ligar e desligar luzes.
Com essa implementação, aprendemos como personalizar o modelo de reconhecimento de voz, o que permite a oportunidade de explorar diferentes datasets e aprimorar o sistema com novos comandos. O desafio proposto de usar uma base de dados própria ou outra disponível online abre portas para diferentes aplicações que você deseje construir.
Acesse o repositório do projeto em: https://github.com/Graziele-Rodrigues/ReconhecimentoComandoVoz














