
Este artigo demonstra a codificação em VHDL de uma CPU de 8 bits bastante simples, a Ahmes. O código foi simulado na ferramenta Quartus e deve servir apenas como referência didática para compreender como uma CPU executa uma sequência de instruções.
Há cerca de nove anos, durante um curso de pós-graduação que frequentei no CEFET-SC, fui apresentado, na disciplina de arquitetura de computadores, às CPUs hipotéticas criadas na UFRGS (Neander, Ahmes, Ramses e Cesar) pelo professor Raul Fernando Weber.
Posteriormente, na disciplina de lógica programável, o nosso professor, Francisco Edson Nogueira de Melo, propôs que os alunos fizessem a implementação de circuitos ou aplicações práticas utilizando lógica programável e VHDL. Apesar de não ser o meu primeiro contato com VHDL (eu já havia participado de um mini-curso do grande Augusto Einsfeldt), eu nunca havia implementado nada em lógica programável.
Foi então que eu percebi a possibilidade de literalmente unir o útil ao agradável e realizar um antigo sonho: utilizando VHDL seria possível implementar uma CPU básica capaz de executar um conjunto de instruções e demonstrar os principais conceitos relacionados à execução de código sequencial!

Os Melhores Treinamentos sobre Sistemas embarcados e IoT
Cursos com professores qualificados para acelerar sua carreira e projetos
Então, juntamente com o meu amigo e colega de curso Roberto do Amaral, decidimos implementar em VHDL uma das CPUs hipotéticas da UFRGS que já haviam sido objeto de estudos na disciplina de arquitetura de computadores. Escolhemos a máquina Ahmes por incluir um conjunto de instruções bastante funcional e uma arquitetura muito simples.
A Máquina Ahmes
O modelo de programação da máquina Ahmes é absolutamente enxuto: trata-se de uma arquitetura de 8 bits, com um conjunto de 24 instruções, três registradores e um único modo de endereçamento!
Dada a sua simplicidade, não existe implementação de uma pilha e o uso de sub-rotinas é prejudicado (apesar de ser possível limitadamente através de código auto-modificável), há também a limitação imposta pela capacidade máxima de endereçamento de 256 bytes de memória (num espaço único para memória de programa e de dados, seguindo uma arquitetura Von Neumann tradicional).
Dentre os registradores presentes no Ahmes encontramos: um acumulador de 8 bits (AC), um registrador de status com 5 bits (N-negativo, Z-zero, C-carry, B-borrow e V-overflow) e um contador de programa (PC) com 8 bits.
As 24 instruções reconhecidas pelo Ahmes são as seguintes:
Tabela 1 – Conjunto de instruções do Ahmes
|
Opcode binário |
Mnemônico |
Descrição |
Comentário |
|
0000 0000 |
NOP |
nenhuma operação |
nenhuma operação |
|
0001 0000 |
STA end |
MEM(end) ← AC |
armazena o conteúdo do acumulador no endereço de memória especificado |
|
0010 0000 |
LDA end |
AC← MEM(end) |
carrega o acumulador com conteúdo da memória |
|
0011 0000 |
ADD end |
AC← MEM(end) + AC |
soma o acumulador com conteúdo da memória |
|
0100 0000 |
OR end |
AC← MEM(end) OR AC |
operação ‘ou’ lógico |
|
0101 0000 |
AND end |
AC← MEM(end) AND AC |
operação ‘e’ lógico |
|
0110 0000 |
NOT |
AC← NOT AC |
complemento de um do acumulador |
|
0111 0000 |
SUB end |
AC← MEM(end) – AC |
subtrai acumulador do conteúdo da memória |
|
1000 0000 |
JMP end |
PC ← end |
desvio incondicional para o endereço |
|
1001 0000 |
JN end |
se N=1 então PC ← end |
desvio condicional se negativo |
|
1001 0100 |
JP end |
se N=0 então PC ← end |
desvio condicional se positivo |
|
1001 1000 |
JV end |
se V=1 então PC ← end |
desvio condicional se houve estouro |
|
1001 1100 |
JNV end |
se V=0 então PC ← end |
desvio condicional se não houve estouro |
|
1010 0000 |
JZ end |
se Z=1 então PC ← end |
desvio condicional se zero |
|
1010 0100 |
JNZ end |
se Z=0 então PC ← end |
desvio condicional se diferente de zero |
|
1011 0000 |
JC end |
se C=1 então PC ← end |
desvio condicional se foi um |
|
1011 0100 |
JNC end |
se C=0 então PC ← end |
desvio condicional se não foi um |
|
1011 1000 |
JB end |
se B=1 então PC ← end |
desvio condicional se emprestou um |
|
1011 1100 |
JNB end |
se B=0 então PC ← end |
desvio condicional se não emprestou um |
|
1110 0000 |
SHR |
C←AC(0); AC(i-1)←AC(i); AC(7)← 0 |
deslocamento para a direita |
|
1110 0001 |
SHL |
C←AC(7); AC(i)←AC(i-1); AC(0)←0 |
deslocamento para a esquerda |
|
1110 0010 |
ROR |
C←AC(0); AC(i-1)←AC(i); AC(7)←C |
rotação para a direita |
|
1110 0011 |
ROL |
C←AC(7); AC(i)←AC(i-1); AC(0)←C |
rotação para a esquerda |
|
1111 0000 |
HLT |
parada |
termina a execução (aguarda um reset) |
Em razão das especificações básicas não incluírem os tempos de execução das instruções, tomamos a liberdade de escolher uma implementação que fosse o mais simples possível (compatível com os nossos limitados conhecimentos sobre VHDL e lógica programável).
A figura 1 mostra o esquemático de alto nível do Ahmes. Podemos ver que existem três blocos: a CPU Ahmes propriamente dita, uma ULA (unidade lógica e aritmética) e um bloco de memória. Repare que o bloco de memória está presente apenas para fins de validação de simulação, numa implementação real ele seria substituído por memórias ROM/FLASH e RAM externas.

Implementação VHDL do Ahmes
A implementação VHDL do Ahmes foi dividida em duas partes. A ULA (Unidade Lógica e Aritmética), responsável pelas operações lógicas e aritméticas da CPU, foi implementada em um bloco e código separados, permitindo que se testasse a mesma independentemente do restante da CPU.
O bloco da ULA é bastante simples: ela possui um barramento de 4 bits para seleção da operação desejada, dois barramentos de 8 bits para os operandos de entrada e um barramento de 8 bits para o resultado. Há também linhas de saída para os flags N, Z, C, B e V e uma linha adicional de entrada de transporte, utilizada nas operações de rotação de bits (ROR e ROL).
O código VHDL da mesma é igualmente simples, já que a ULA consiste basicamente num circuito lógico combinacional com poucas operações implementadas.
LIBRARY ieee ;
USE ieee.std_logic_1164.all ;
USE ieee.std_logic_unsigned.all ;
ENTITY ula IS
PORT
(
operacao : IN STD_LOGIC_VECTOR (3 DOWNTO 0);
operA : IN STD_LOGIC_VECTOR(7 DOWNTO 0);
operB : IN STD_LOGIC_VECTOR(7 DOWNTO 0);
Result : buffer STD_LOGIC_VECTOR(7 DOWNTO 0);
Cin : IN STD_LOGIC;
N,Z,C,B,V : buffer STD_LOGIC
);
END ula;
ARCHITECTURE ula1 OF ula IS
constant ADIC : STD_LOGIC_VECTOR(3 DOWNTO 0):="0001";
constant SUB : STD_LOGIC_VECTOR(3 DOWNTO 0):="0010";
constant OU : STD_LOGIC_VECTOR(3 DOWNTO 0):="0011";
constant E : STD_LOGIC_VECTOR(3 DOWNTO 0):="0100";
constant NAO : STD_LOGIC_VECTOR(3 DOWNTO 0):="0101";
constant DLE : STD_LOGIC_VECTOR(3 DOWNTO 0):="0110";
constant DLD : STD_LOGIC_VECTOR(3 DOWNTO 0):="0111";
constant DAE : STD_LOGIC_VECTOR(3 DOWNTO 0):="1000";
constant DAD : STD_LOGIC_VECTOR(3 DOWNTO 0):="1001";
BEGIN
process (operA, operB, operacao,result,Cin)
variable temp : STD_LOGIC_VECTOR(8 DOWNTO 0);
begin
case operacao is
when ADIC =>
temp := ('0'&operA) + ('0'&operB);
result <= temp(7 DOWNTO 0);
C <= temp(8);
if (operA(7)=operB(7)) then
if (operA(7) /= result(7)) then V <= '1';
else V <= '0';
end if;
else V <= '0';
end if;
when SUB =>
temp := ('0'&operA) - ('0'&operB);
result <= temp(7 DOWNTO 0);
B <= temp(8);
if (operA(7) /= operB(7)) then
if (operA(7) /= result(7)) then V <= '1';
else V <= '0';
end if;
else V <= '0';
end if;
when OU =>
result <= operA or operB;
when E =>
result <= operA and operB;
when NAO =>
result <= not operA;
when DLE =>
C <= operA(7);
result(7) <= operA(6);
result(6) <= operA(5);
result(5) <= operA(4);
result(4) <= operA(3);
result(3) <= operA(2);
result(2) <= operA(1);
result(1) <= operA(0);
result(0) <= Cin;
when DAE =>
C <= operA(7);
result(7) <= operA(6);
result(6) <= operA(5);
result(5) <= operA(4);
result(4) <= operA(3);
result(3) <= operA(2);
result(2) <= operA(1);
result(1) <= operA(0);
result(0) <= '0';
when DLD =>
C <= operA(0);
result(0) <= operA(1);
result(1) <= operA(2);
result(2) <= operA(3);
result(3) <= operA(4);
result(4) <= operA(5);
result(5) <= operA(6);
result(6) <= operA(7);
result(7) <= Cin;
when DAD =>
C <= operA(0);
result(0) <= operA(1);
result(1) <= operA(2);
result(2) <= operA(3);
result(3) <= operA(4);
result(4) <= operA(5);
result(5) <= operA(6);
result(6) <= operA(7);
result(7) <= '0';
when others =>
result <= "00000000";
Z <= '0';
N <= '0';
C <= '0';
V <= '0';
B <= '0';
end case;
if (result="00000000") then
Z <= '1'; else Z <= '0';
end if;
N <= result(7);
end process;
END ula1;
O código VHDL da CPU Ahmes é um pouco mais complexo e mais extenso, por isso, vamos explicar a implementação de apenas três instruções: uma de manipulação de dados, uma de aritmética (que faz uso da ULA) e outra de desvio.
A decodificação é baseada em uma máquina de estados que utiliza uma variável interna chamada CPU_STATE cujo estado é controlado/avançado por um evento de subida da linha de clock da CPU.
Note que nos dois primeiros estágios (ou clocks) da decodificação da instrução, a CPU precisa fazer o trabalho “braçal” de buscar o operando na memória e então carregá-lo num registrador interno chamado INSTR, que irá conter o opcode da instrução.
CASE CPU_STATE IS -- verifica o estado atual da máquina de estados
WHEN BUSCA => -- primeiro ciclo da busca de instrução
ADDRESS_BUS <= PC; -- carrega o barramento de endereços com o PC
ERROR <= '0'; -- força a saída de erros para zero
CPU_STATE := BUSCA1; -- avança para o estado BUSCA1
WHEN BUSCA1 =>-- segundo ciclo da busca de instrução
INSTR := DATA_IN; -- lê a instrução e armazena em INSTR
CPU_STATE := DECOD; -- avança para o próximo estágio
WHEN DECOD => -- início da decodificação de instrução
CASE INSTR IS -- decod the INSTR content
-- NOP - não faz nada, apenas avança o PC
WHEN NOP =>
PC := PC + 1; -- soma 1 ao PC
CPU_STATE := BUSCA; -- reinicia máquina de estados
-- STA - armazena o AC no endereço especificado pelo operando
WHEN STA =>
-- incrementa o endereço (para apontar para o operando)
ADDRESS_BUS <= PC + 1;
-- segue para a decodificação da STA
CPU_STATE := DECOD_STA1;
Somente no terceiro pulso de clock é que o processo de decodificação do opcode efetivamente tem início. No fragmento de código acima podemos identificar uma instrução NOP e o processamento relacionado a ela (que é nulo, resumindo-se simplesmente ao incremento do PC para apontar para a próxima instrução). Também podemos ver a parte inicial da decodificação de uma instrução STA. Neste caso, observamos que o barramento de endereços é carregado com PC+1, de forma que o operando da instrução possa ser lido e, em seguida, o estado da máquina avança para o primeiro estágio de decodificação da instrução (DECOD_STA1).
Neste momento é importante ressaltar que este código é resultado de uma primeira e despretensiosa implementação. Apesar de funcional, há uma série de alterações que podem ser feitas para tornar o processo de decodificação mais eficiente, uma delas seria fazer o incremento do PC já no segundo estágio de decodificação.
Prosseguindo com a decodificação da instrução STA, vejamos o restante do código VHDL relacionado à mesma:
WHEN DECOD_STA1 => -- decodificação da instrução STA
TEMP := DATA_IN; -- lê o operando
CPU_STATE := DECOD_STA2;
WHEN DECOD_STA2 =>
ADDRESS_BUS <= TEMP;
DATA_OUT <= AC;-- coloca o acumulador na saída de dados
PC := PC + 1; -- incrementa o PC
CPU_STATE := DECOD_STA3;
WHEN DECOD_STA3 =>
MEM_WRITE <= '1';-- ativa a escrita na memória
-- incrementa o PC (aponta para a próxima instrução)
PC := PC + 1;
CPU_STATE := DECOD_STA4;
WHEN DECOD_STA4 =>
MEM_WRITE <= '0';-- desativa a escrita na memória
CPU_STATE := BUSCA;-- termina a decod da instrução STA
No quarto estágio de decodificação o operando de entrada (endereço de memória onde será armazenado o conteúdo do acumulador) é lido e armazenado numa variável temporária (TEMP). Em seguida o mesmo é colocado no barramento de endereços (para selecionar o endereço de memória) e o acumulador é colocado no barramento de dados.
No sexto estágio o valor é escrito na memória e no último estágio (sétimo) a linha de escrita é desativada e a CPU retorna ao estado inicial de busca de instrução.
Vejamos agora a decodificação de uma instrução ADD. Os dois primeiros estágios são os mesmos já vistos antes. A diferenciação acontece no terceiro estágio, quando é lido o operando da instrução:
WHEN ADD => -- incrementa o endereço (para apontar para o operando) ADDRESS_BUS <= PC + 1; -- segue para a decodificação da ADD CPU_STATE := DECOD_ADD1;
Os demais estágios prosseguem com a decodificação. Veja que no sexto estágio (DECOD_ADD3) é onde a “mágica” acontece: os operandos são carregados na ULA e a operação é selecionada (ADD). Em seguida a decodificação segue para um último estágio comum a várias instruções que é o DECOD_STORE, quando o resultado proveniente da ULA é armazenado no acumulador.
WHEN DECOD_ADD1 => -- decodificação da instrução ADD
TEMP := DATA_IN;-- carrega o operando (endereço)
CPU_STATE := DECOD_ADD2;
WHEN DECOD_ADD2 =>
-- coloca o endereço do operando no barramento de endereços
ADDRESS_BUS <= TEMP;
CPU_STATE := DECOD_ADD3;
WHEN DECOD_ADD3 =>
OPER_A <= DATA_IN; -- coloca o dado na entrada OPER_A da ULA
OPER_B <= AC; -- carrega a entrada OPER_B da ULA com o acumulador
OPERACAO <= ULA_ADD; -- especifica a operação ADD na ULA
PC := PC + 1; -- incrementa o PC
CPU_STATE := DECOD_STORE;
WHEN DECOD_STORE =>
AC := RESULT; -- carrega o resultado da ULA no acumulador
PC := PC + 1; -- incrementa o PC
CPU_STATE := BUSCA; -- termina a decodificação da instrução
A última instrução que veremos é a JZ (não é o rapper) que é pula se zero. A decodificação da mesma é bastante simples, com os dois primeiros estágios iguais aos das demais instruções. A decodificação do opcode (terceiro estágio) implementa o seguinte código:
WHEN JZ => -- desvia para o endereço se Z=1
IF (Z='1') THEN
-- se Z=1 aponta para o oper. da instrução
ADDRESS_BUS <= PC + 1;
CPU_STATE := DECOD_JMP;-- prossegue como um JMP
ELSE
-- se Z=0
PC := PC + 2; -- avança o PC
CPU_STATE := BUSCA; -- retorna ao estado de busca
END IF;
O estágio seguinte (quarto) é comum a todas as instruções de desvio e carrega o PC com o operando da instrução, o que faz o desvio propriamente dito:
WHEN DECOD_JMP => -- decodificação da instrução JMP (JMP decoding) PC := DATA_IN;-- carrega o dado lido (operando) no PC CPU_STATE := BUSCA; -- termina a decodificação da instrução JMP
O restante das instruções segue a mesma filosofia e acredito que o código VHDL amplamente comentado facilita o entendimento da operação do Ahmes.
Como já dito, a CPU Ahmes foi testada somente dentro do ambiente de simulação da ferramenta Quartus II da Altera. Para facilitar os testes, foi criada uma memória em VHDL que funciona como ROM e RAM ao mesmo tempo. Os endereços 0 a 24 são inicializados com um pequeno programa assembly que testa algumas funções do Ahmes, ao passo que os endereços 128 a 132 armazenam variáveis do programa. O código da mesma é o seguinte:
LIBRARY ieee ; USE ieee.std_logic_1164.all ; USE ieee.std_logic_unsigned.all ; ENTITY memoria IS PORT ( address_bus : IN INTEGER RANGE 0 TO 255; data_in : IN INTEGER RANGE 0 TO 255; data_out : OUT INTEGER RANGE 0 TO 255; mem_write : IN std_logic; rst : IN std_logic ); END memoria; ARCHITECTURE MEMO OF MEMORIA IS constant NOP : INTEGER := 0; constant STA : INTEGER := 16; constant LDA : INTEGER := 32; constant ADD : INTEGER := 48; constant IOR : INTEGER := 64; constant IAND: INTEGER := 80; constant INOT: INTEGER := 96; constant SUB : INTEGER := 112; constant JMP : INTEGER := 128; constant JN : INTEGER := 144; constant JP : INTEGER := 148; constant JV : INTEGER := 152; constant JNV : INTEGER := 156; constant JZ : INTEGER := 160; constant JNZ : INTEGER := 164; constant JC : INTEGER := 176; constant JNC : INTEGER := 180; constant JB : INTEGER := 184; constant JNB : INTEGER := 188; constant SHR : INTEGER := 224; constant SHL : INTEGER := 225; constant IROR: INTEGER := 226; constant IROL: INTEGER := 227; constant HLT : INTEGER := 240; TYPE DATA IS ARRAY (0 TO 255) OF INTEGER; BEGIN process (mem_write,rst) VARIABLE DATA_ARRAY: DATA; BEGIN IF (RST='1') THEN -- Contador decrescente de 10 (conteúdo do endereço 130) até 0 DATA_ARRAY(0) := LDA; -- Carrega A com (130) (A=10) DATA_ARRAY(1) := 130; DATA_ARRAY(2) := SUB; -- Subtrai (132) de A (A=A-1) DATA_ARRAY(3) := 132; DATA_ARRAY(4) := JZ; -- Salta para 8 se A=0 DATA_ARRAY(5) := 8; DATA_ARRAY(6) := JMP; -- Salta para o endereço 2 (loop) DATA_ARRAY(7) := 2; -- Terminou a contagem, agora faz a soma de (130) com (131) e salva em (128) DATA_ARRAY(8) := LDA; -- Carrega A com (130) (A=10) DATA_ARRAY(9) := 130; DATA_ARRAY(10) := ADD; -- Soma A com (131) (A=10+18) DATA_ARRAY(11) := 131; DATA_ARRAY(12) := STA; -- Guarda A em (128) DATA_ARRAY(13) := 128; -- Agora faz um OR de (128) com (129) rotacionado 4 bits à esquerda, salva o resultado em (133) DATA_ARRAY(14) := LDA; -- Carrega A com (129) DATA_ARRAY(15) := 129; DATA_ARRAY(16) := SHL; -- Desloca A 1 bit à esquerda (o LSB é zero) DATA_ARRAY(17) := SHL; -- Desloca A 1 bit à esquerda (o LSB é zero) DATA_ARRAY(18) := SHL; -- Desloca A 1 bit à esquerda (o LSB é zero) DATA_ARRAY(19) := SHL; -- Desloca A 1 bit à esquerda (o LSB é zero) DATA_ARRAY(20) := IOR; -- OU lógico de A com (128) DATA_ARRAY(21) := 128; DATA_ARRAY(22) := STA; -- Guarda o resultado em (133) DATA_ARRAY(23) := 133; DATA_ARRAY(24) := HLT; -- Pára o processamento -- Variáveis e constantes utilizadas no programa DATA_ARRAY(128) := 0; DATA_ARRAY(129) := 5; DATA_ARRAY(130) := 10; DATA_ARRAY(131) := 18; DATA_ARRAY(132) := 1; ELSIF (RISING_EDGE(MEM_WRITE)) THEN DATA_ARRAY(ADDRESS_BUS) := DATA_IN; END IF; DATA_OUT <= DATA_ARRAY(ADDRESS_BUS); end process; END MEMO;
O código assembly armazenado na memória é o seguinte:
LDA 130 SUB 132 JZ 8 JMP 2 LDA 130 ADD 131 STA 128 LDA 129 SHL SHL SHL SHL IOR 128 STA 133 HLT
Ainda para fins de simulação, utilizamos um arquivo de formas de onda que inclui um sinal de clock e um pulso de reset:
Após a compilação do projeto (ou síntese) o resultado é uma CPU que ocupa 222 células lógicas e 99 registradores, mais 82 células lógicas para a ULA, ou seja, um total de 284 células lógicas e 99 registradores, apenas 6,2% das células lógicas e 2,1% dos registradores disponíveis em um FPGA Altera Cyclone II EP2C5, o modelo utilizado na simulação aqui apresentada.
Note que foi utilizada a ferramenta Quartus II Web Edition versão 9.1sp2, uma vez que a última versão do Quartus (prime 16.0) apresentou alguns problemas de instalação, especialmente da ferramenta de simulação Modelsim (provavelmente algum conflito no meu notebook).
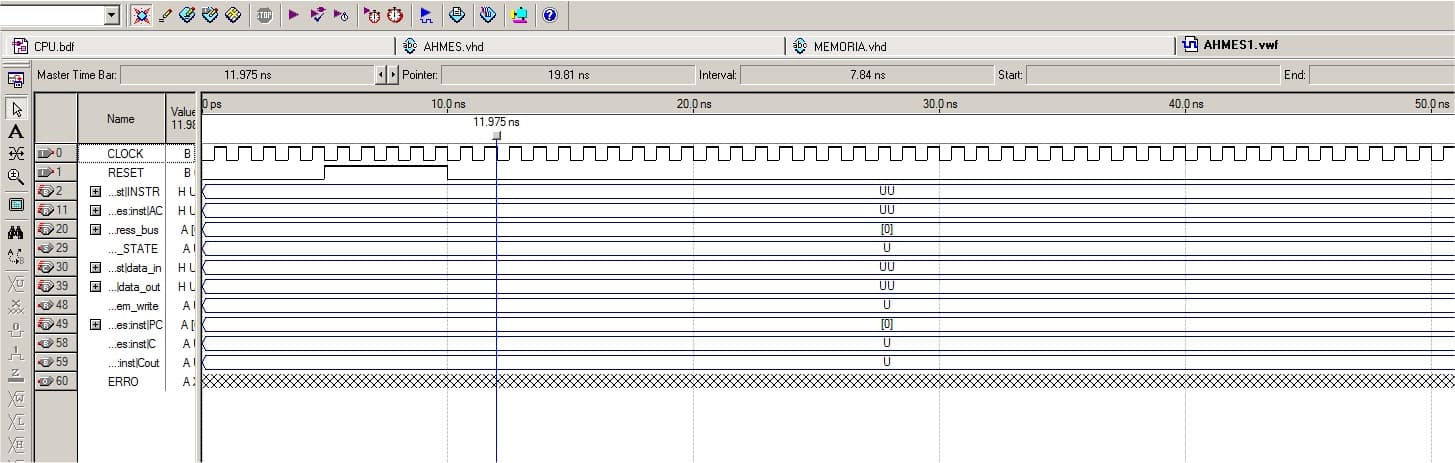
A seguir podemos observar uma parte do arquivo final resultante da simulação da operação do Ahmes. Ele mostra a sequência completa da instrução LDA 130:

Conclusão
Este artigo pretendeu demonstrar que implementar uma CPU não é nenhuma tarefa absurda e, apesar de não termos implementado fisicamente o Ahmes num FPGA, toda a base para o entendimento de como opera um microprocessador está aqui.
Espero que este artigo possa inspirar outras pessoas a estudar a operação e implementação de CPUs em VHDL, pois, ao menos para mim, entender a operação e criar CPUs é algo absolutamente prazeroso e entusiasmante!
Todos os arquivos do Ahmes estão disponíveis para download na minha conta no GitHub.















Um excelente artigo
Excelente artigo ! Venho desenvolvendo alguns projetos em FPGA há algum tempo, mas apenas projetos de sistemas digitais simples e alguns projetos com o Nios II. Estava pensando há algum tempo em tentar desenvolver alguma CPU, mas sempre ficava com a ideia na cabeça de que seria algo muito complicado. Seu artigo me mostrou que é uma tarefa muito menos complexa do que eu imaginava, muito obrigado !!!
Isso aí Diego! Se precisar de alguma ajuda ou quiser discutir algum pontos do seu projeto, entre em contato conosco. Sinta-se a vontade para escrever um artigo e compartilhar sua implementação no site.